In a monolithic application, communication between various modules is often taken for granted, as it occurs seamlessly within the same process through function calls. However, this luxury cannot be maintained in a Microservices architecture. Here, services run in distinct processes, typically separated by a network, and this introduces a lot of challenges. The safety net of in-process communication is lost, giving rise to issues such as unreliable network connections, latency, and service unavailability. Thus, in this architectural paradigm, the communication mechanism must be meticulously crafted with these critical factors in mind.
In a microservices application, there are various types of communication mechanisms to choose from, each with its own set of advantages and disadvantages. Let's dive deeper into the discussion of two of these communication methods.
Synchronous Communication
Synchronous communication is a communication protocol where the client initiates a request and then waits for the server to respond before proceeding with its operations. In this scenario, each request must be processed by exactly one server and the server is expected to provide an immediate response to the caller. Once the client receives this response, it can then proceed with its subsequent operations. A common example of a synchronous protocol is HTTP/HTTPS, which is frequently used in client-to-server communication within microservices applications.
Why Not Synchronous Communication?
In microservice applications where synchronous communication methods are extensively used for inter-service communication, complexity can quickly escalate. This approach often results in a convoluted network of services calling other services, leading to long call chains. Each service in this chain must wait for the downstream service to provide a response, which can considerably extend the overall time it takes to fulfill a user's request. Unfortunately, this prolonged processing time can significantly hamper system performance and have a negative impact on the user experience.
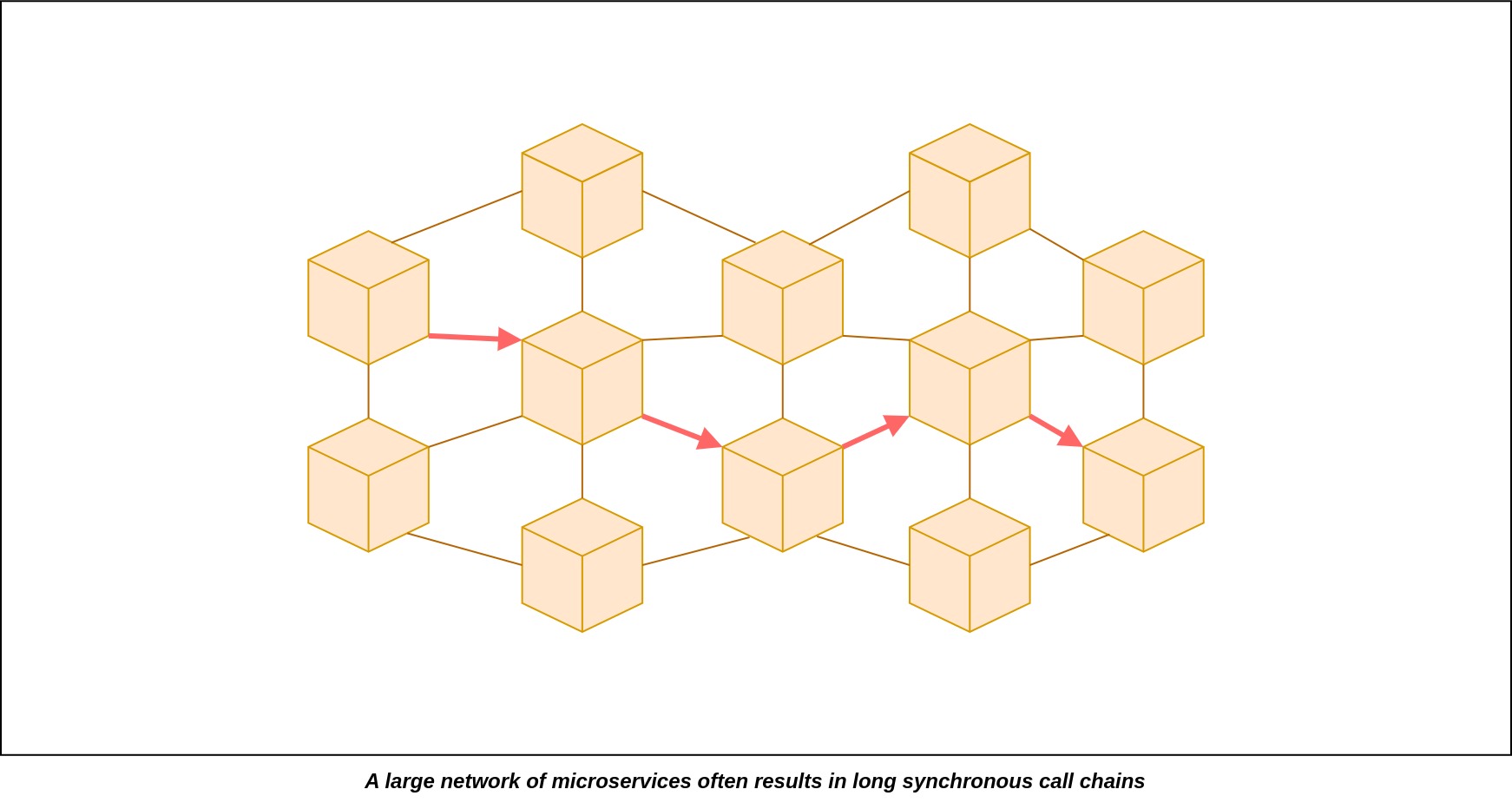
In a microservices architecture, it's crucial for each microservice to operate autonomously, meaning it should function independently without needing to be aware of other microservices. However, when microservices use synchronous communication protocols, they become aware of and dependent on each other. This creates a tight runtime coupling, where all the involved services must be available simultaneously. As the chain of synchronous calls grows longer, the requirement for all services to be continuously available becomes more demanding. If any service in this chain experiences downtime or an issue, it can disrupt the entire process, leading to unfulfilled requests.
When there are long call chains within a system, it introduces a notable risk. If a microservice deeper in the chain encounters a failure, this failure can potentially cascade to affect other parts of the system. This domino effect of failures can disrupt the entire application, leading to widespread service degradation and possible downtime, ultimately compromising the reliability and robustness of the entire system.
Furthermore, the overall reliability and availability of the application can experience a significant decline. For instance, consider a scenario where the order service relies on both the user service and the product service to fulfill a user's request. In this case, for the application to function seamlessly, all three services must be available simultaneously. However, if each of these services individually has an availability rate of 99.3%, the overall service availability drops notably to 97.91%. This reduction in availability can be quite substantial and has the potential to disrupt the application's performance and reliability.
Asynchronous Communication
In this communication protocol, the client and server do not follow the traditional request-response model of communication. In this context, the client can initiate a request, but the server does not provide an immediate response. Instead, the server can perform certain operations on its side to fulfill the client's request at a later time. Optionally, it may send responses to the client after it has completed the task. One notable feature of this protocol is that a single message can be read and processed by multiple servers simultaneously. This messaging style is referred to as the pub/sub (publish/subscribe) pattern.Typically, this is accomplished through the use of asynchronous messaging facilitated by various message queues or service bus tools.
A microservice can be categorized as asynchronous when it either doesn't initiate requests to other services during the processing of a request, or it initiates requests to other services but doesn't halt its operations to wait for the result.
Zero Communication During Request Processing
A microservice can be designed to function without the need for immediate communication with other services during request processing. Instead, it typically interacts with other services at a different time. A straightforward example of this approach involves data replication from other services into the microservice receiving request. In this scenario, the microservice employs messaging or other asynchronous methods to synchronize data with its own system. This proactive data replication eliminates the necessity to make frequent calls to other services when a client initiates a request. By ensuring that the required data is locally available in the desired format, the microservice can efficiently serve incoming requests without the overhead of repeated calls to external services.
Communication Without Waiting For Response
If a microservice can initiates a request to another microservice but doesn't require or wait for a response, the microservice can be categorized as asynchronous. For instance, consider a microservice responsible for managing users. When a new user registers, the User mircoservice can send a request to another microservice responsible for sending emails to users. In this case, the first microservice doesn't need to await a response from the other service; its primary goal is to trigger the email notification, and it can continue processing other tasks without waiting for confirmation of email delivery.
Addressing Issues of Synchronous Communication Through Asynchronous Methods
Asynchronous communication is an effective way to tackle problems posed by synchronous communication. In this approach, both the client and the services communicate asynchronously by exchanging messages through messaging channels. Notably, no participant in this communication is ever blocked waiting for an immediate response.
This architecture offers remarkable resilience because it leverages a message queue that buffers messages until they are ready to be consumed. Messages sit in the buffer, patiently waiting for their turn to be processed. This means that even if a service experiences downtime or becomes temporarily unavailable, the incoming requests will wait patiently for the service to recover and process the messages. As a result, the system becomes more fault-tolerant and capable of gracefully handling disruptions.
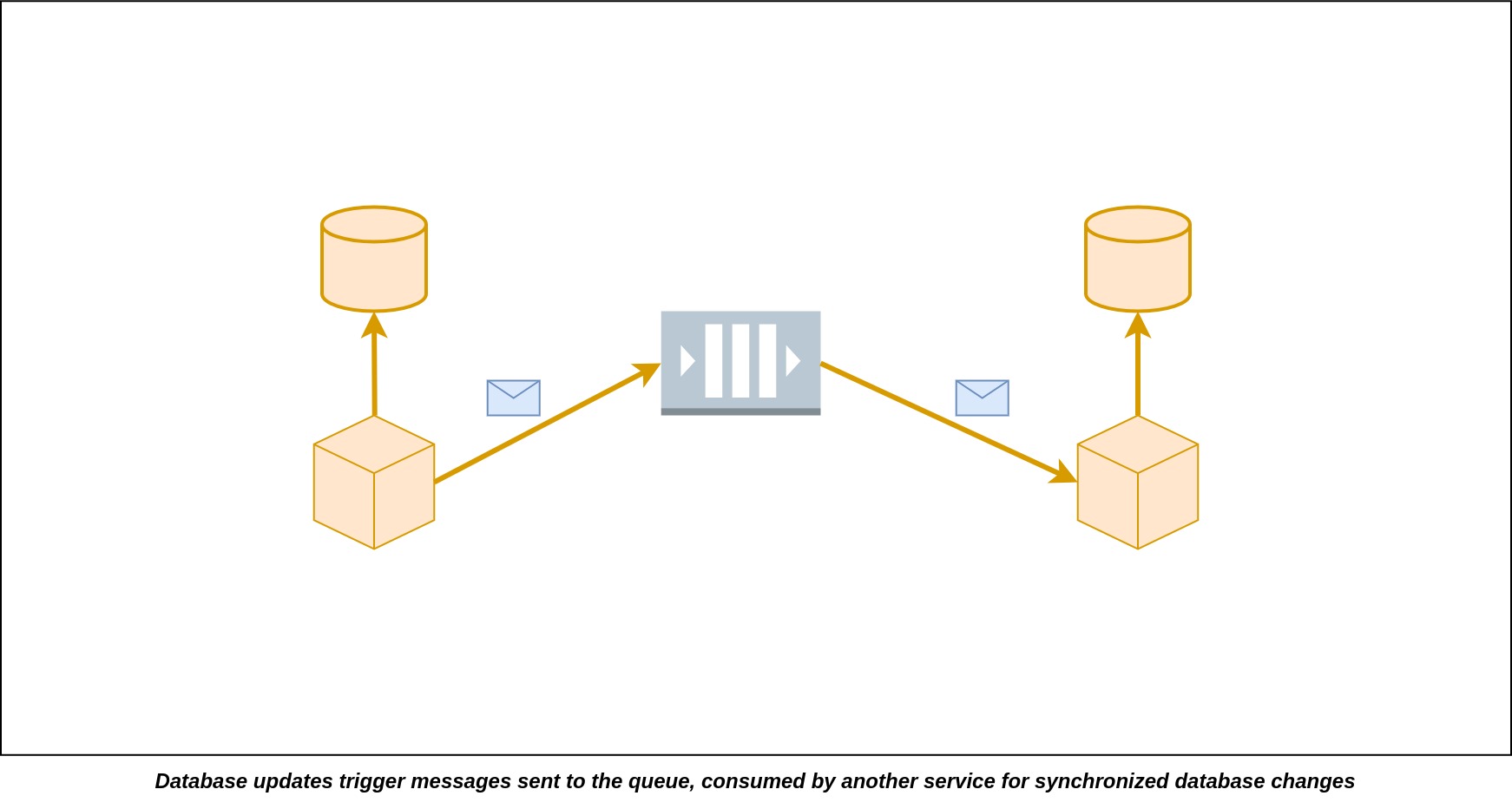
There are several methods for making microservices work asynchronously. As we've discussed earlier, a microservice can be considered asynchronous when it doesn't have to immediately call other services and wait for their immediate responses. One effective way to achieve this is by synchronizing the data needed from other microservices in near real-time. Here's how it works: Whenever there's a change in the data source of a microservice, it sends out an event, essentially a message, into a message queue. The microservices that require this data to fulfill user requests should already be subscribed to the specific topic related to that message queue. When events arrive in that message queue topic, the subscribing microservices promptly receive the event and update their own local databases in the format that is suitable for the microservices to carry out the queries conveniently. Now, a microservice can maintain a local copy of the data from other microservices. When a user request comes in, this microservice doesn't need to call another microservice for the data because it's already available locally. This approach eliminates the requirement for other microservices to be available at the exact moment a user request arrives. It also removes the need for the microservice to be aware of the existence of other microservices. It only needs to subscribe to the types of events it's interested in, reducing the tight coupling between services. Additionally, this leads to improved performance by eliminating long service calls, resulting in a more responsive system.
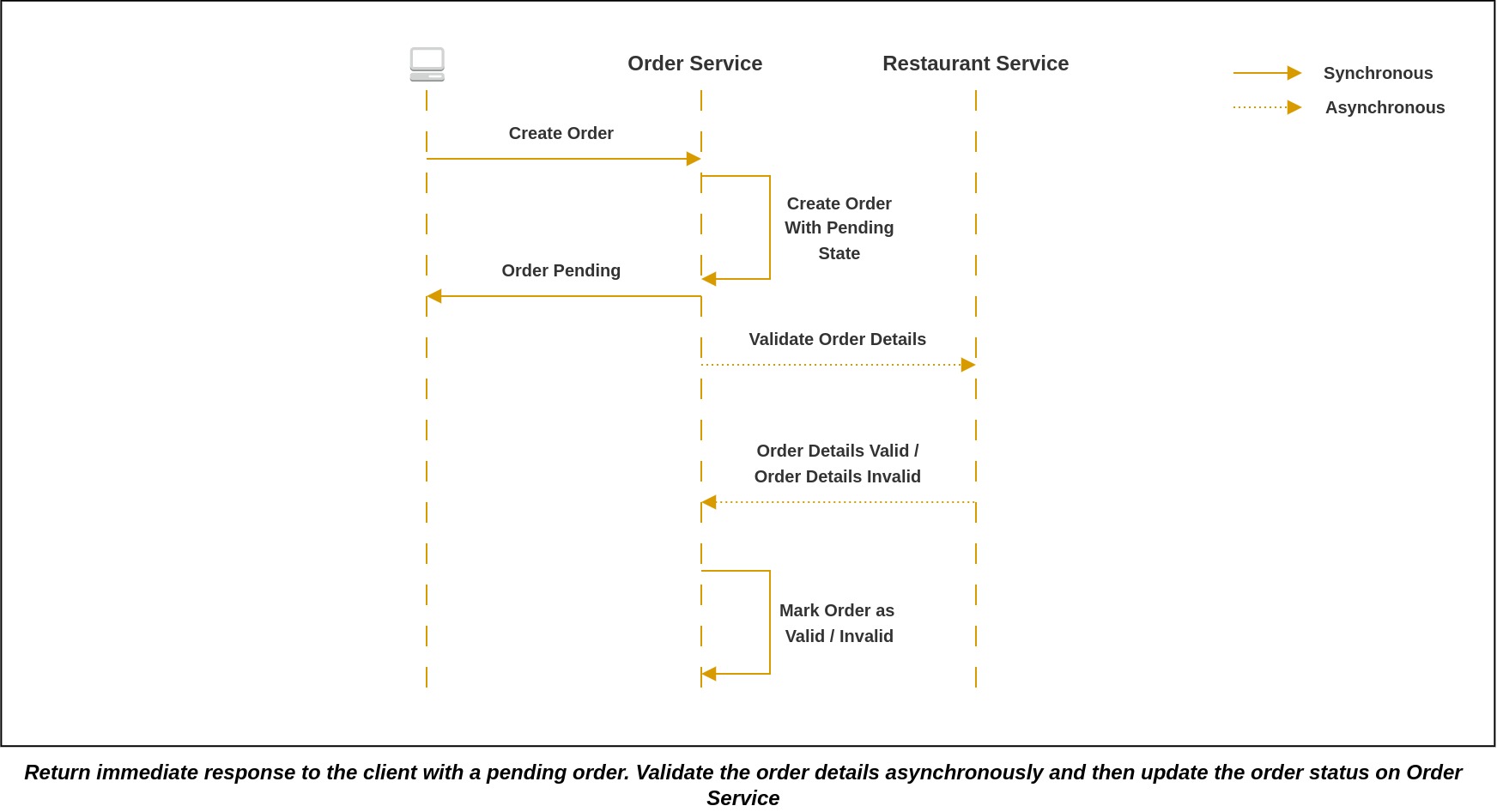
When a microservice needs to initiate an action in another microservice, it's advisable not to carry out this action synchronously. Instead, it's recommended to initiate the request using asynchronous methods, such as sending an event to a message queue. For instance, let's consider a scenario where a user initiates a request with the order microservice to place an order. In response, the order microservice can create the order with a "pending" status and immediately respond to the client. It can then initiate asynchronous communication with other relevant services to validate the order through message exchanges. Upon successful validation, the order microservice will receive a confirmation message indicating that the order has been validated. In response, it will update the order's status in its own database. However, it's worth noting that while this approach offers advantages, it may add some complexity to the client application. The client application may need to periodically poll for updates or subscribe to receive notification messages in order to stay informed about the status of the order. In this way, even if the service that needs to be invoked is temporarily unavailable, the message broker steps in to buffer the message until the service is back online and ready to receive and process it. This effectively resolves the availability issues that can arise with synchronous communication methods.
Messaging
At the core there is messaging which drives the asynchronous communication protocol. A message is made out of a header and a body. The header contains different metadata about of the data being sent along with other information like message id and an optional name of the reply channel which denotes the message channel to use to send a reply in case any reply is expected. The message body is the data that is being sent. Messages are sent over specific channels or topics. Receivers interested in a particular type of message subscribe to the channel or topic that is designated for that type of messages.
Message Types
Document Message
A document message only carries data and leaves it up to the recipients to determine how to handle that data, if necessary. The crucial aspect of a document is its content - the actual data. Ensuring the successful transfer of this document takes precedence, while the specific timing of when it's sent and received is less critical. Documents can accommodate various types of data. They are typically transmitted using a Point-to-Point Channel, allowing the document to be moved from one process to another without unnecessary duplication. In a Request-Reply scenario, the response often takes the form of a Document Message, with the document serving as the result value.
Command Message
A command message is essentially a typical message that carries a specific command within it. Its purpose is to trigger a particular action or functionality on the recipient's end. This message includes both the method to execute and any necessary parameters for that action. Think of it as akin to a remote procedure call (RPC), but with an asynchronous nature, meaning it doesn't require an immediate response. These Command Messages are typically employed within a point-to-point channel to ensure that the command is executed by only one designated recipient.
Event Message
An event message serves as a notification that something significant has occurred within the sender's application. Receivers may subscribe to different types of event messages to react on the events as they occur. While these notifications can technically be conveyed through Remote Procedure Calls (RPC), this approach necessitates the receiving applications to react immediately, and the sending system must maintain a record of all interested parties, dispatching the event to all subscribers, regardless of their readiness to receive it. Instead, events are often transmitted as messages, allowing them to reside in a message queue until subscribers can process them at their convenience. The message queue itself doesn't incorporate any business logic or modify the content of the event in any way. Its primary purpose is to serve as a messaging system that ensures messages ultimately reach all interested parties. The key distinction between events and documents lies in their timing. In events, timeliness is crucial. The sender should dispatch the event promptly upon a change occurring, and the recipient should process it as quickly as possible. Content is typically of secondary importance in events; some events may lack a message body entirely. The mere occurrence of an event may require the subscribers to react on it. Many receivers can be interested in the events of a particular application, so there is no point to send them via Point-to-Point channel. Messages are usually broadcast via a Publish-Subscribe channel so that all interested applications can receive and react on them.
Message Channels
Point-to-Point: In this type of channel, each message is delivered to a single recipient. It's commonly used for sending command messages, where a specific action needs to be triggered on the recipient's end.
Publish-Subscribe: This channel distributes each message to multiple recipients who have subscribed to it. This channel is often preferred for sharing event messages because it allows multiple interested parties to receive notifications about specific events in a system.
Messaging Styles
Asynchronous Request-Response
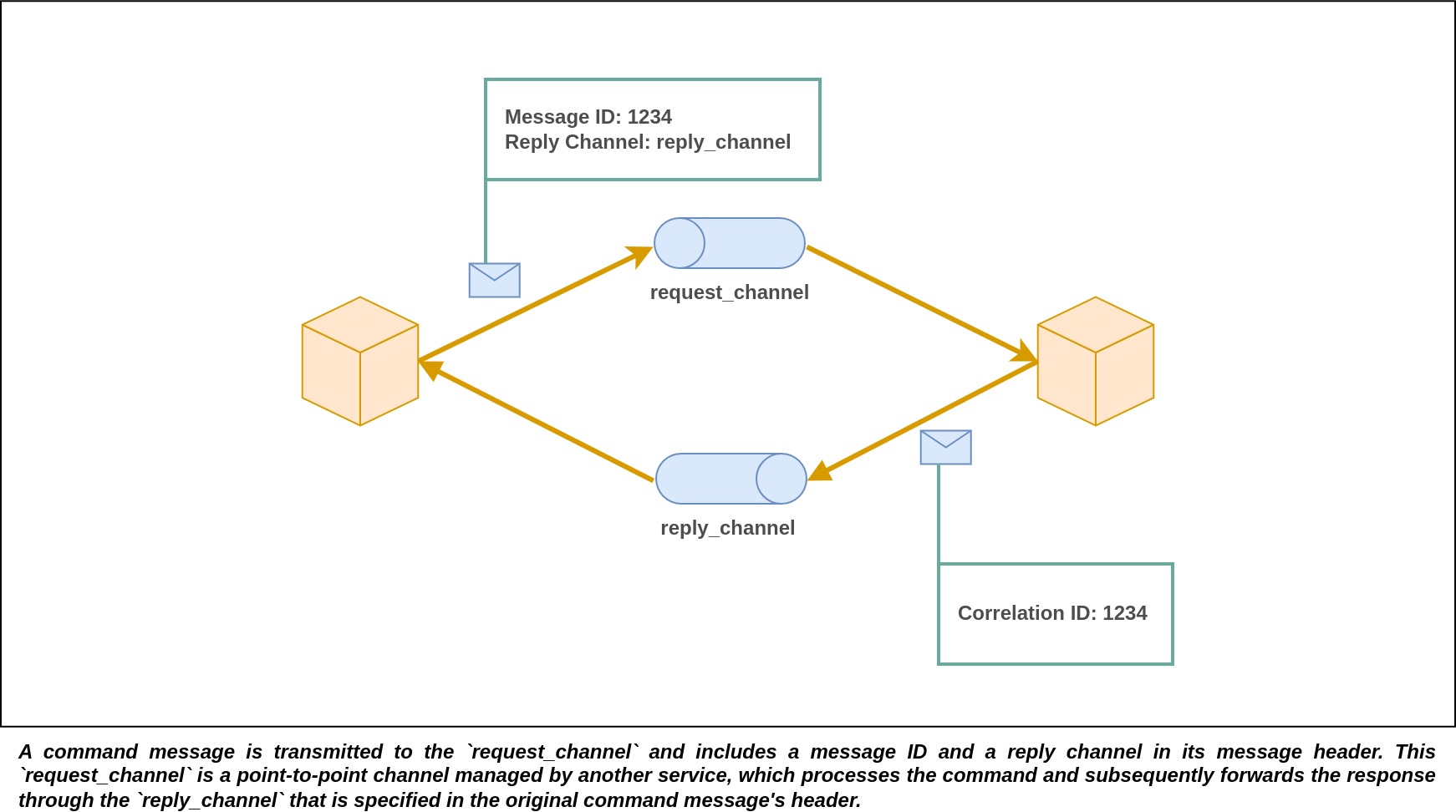
The client sends a command message to a messaging channel owned by a service. This message includes details about the operation to perform and any necessary parameters. The service then handles the request and sends back a reply message containing the result of the operation to a messaging channel owned by the client. To keep track of these exchanges, the client includes a reply channel in the header of the command message it sends. When the server creates the reply message, it includes a correlation ID that matches the original message identifier. This correlation ID is crucial because it helps the client associate the reply message with the original request.
One-way Command
In this scenario, the client sends a message, often in the form of a command, to a dedicated point-to-point channel owned by the service. The service, which actively subscribes to this channel, then processes the received message. It's important to note that in this process, the service does not send any response back to the client.
Publish-Subscribe
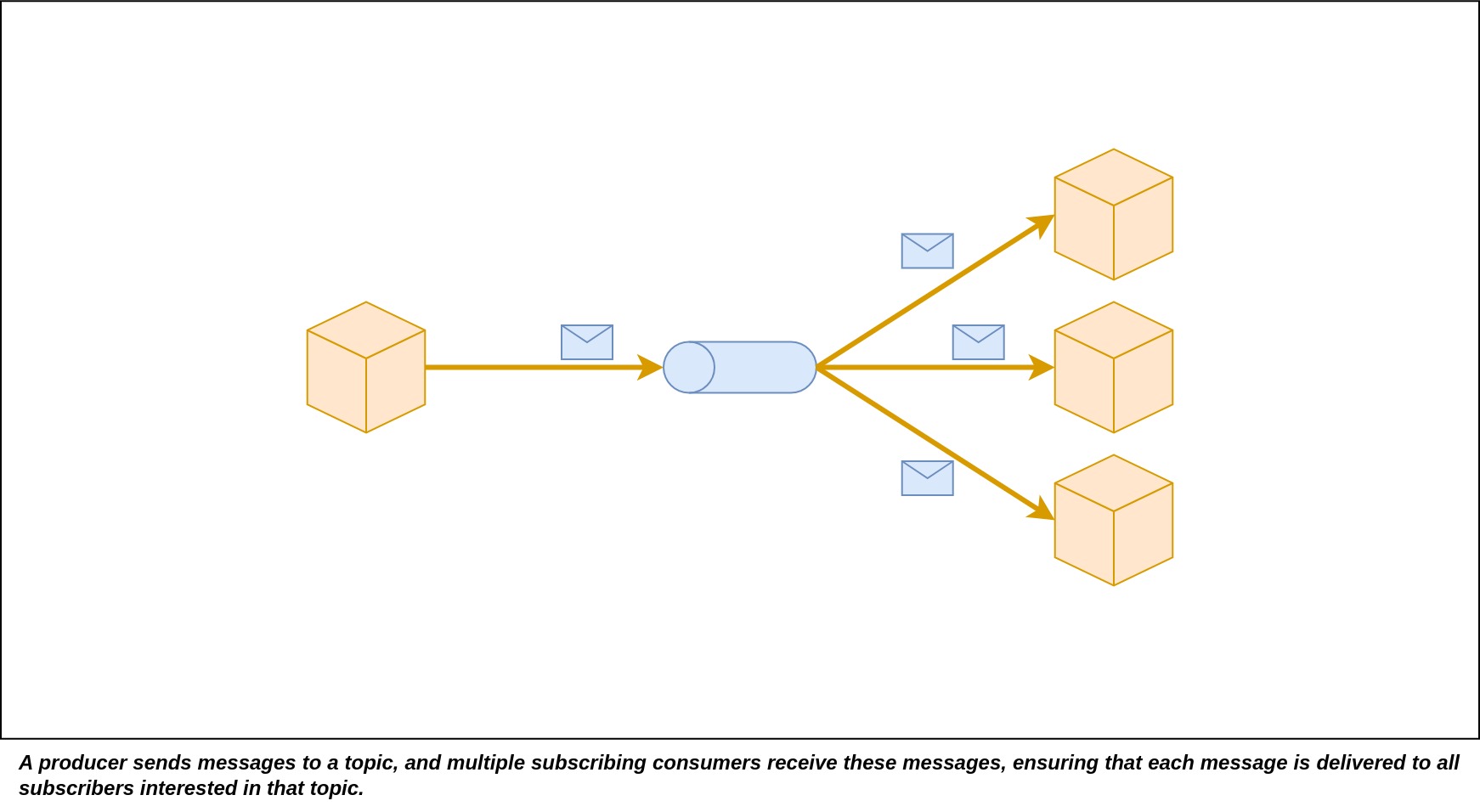
An event message is sent to a channel that has multiple subscribers. This means the message gets delivered to all of these subscribers. The channel itself is owned by the publishing service. An example of this is the publishing of domain events. Different services that want to know about changes in a particular domain can subscribe to the channel for those domain events. When these services receive the events, they can then process them accordingly.
Publish-Responses
The publish-responses style is a more advanced way of communication that blends aspects of both publish/subscribe and request/response. Here's how it works:
- First, a client sends out a message on a publish-subscribe channel. This message includes a special header denoting the name of the channel where the response should be sent.
- Next, a consumer receives this message and prepares a reply. This reply message includes something called a correlation ID with a value the same as the message id of the original message.
- To tie it all together, the client keeps track of all responses using this correlation ID. It uses this ID to match up the received reply messages with the original requests it sent out.
Producer-Broker-Consumer Architecture
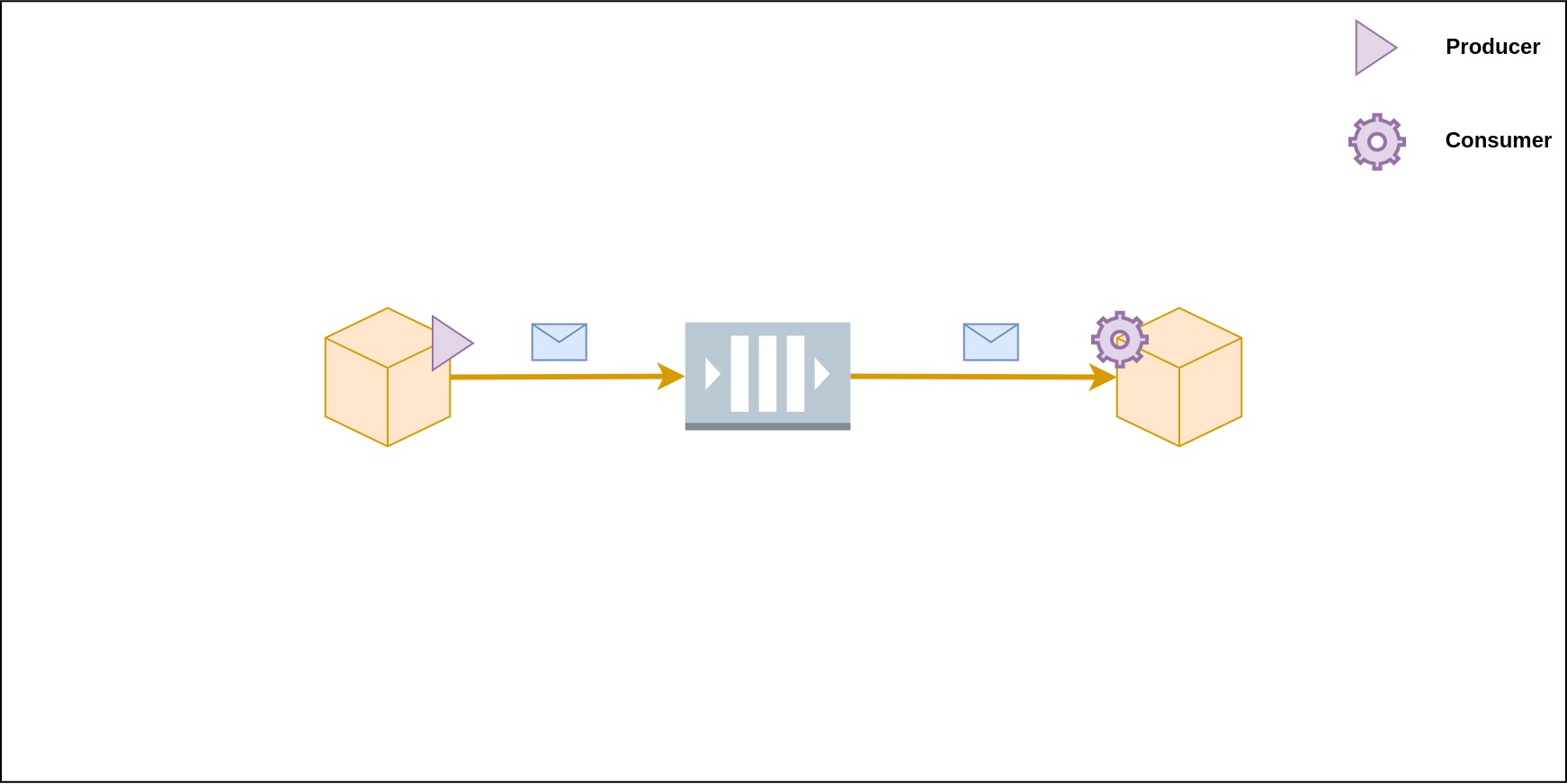
The Producer-Broker-Consumer architecture is a framework for designing and implementing systems where messages need to be efficiently processed and distributed. In this architecture, producers generate messages and send them to a central broker, which acts as an intermediary. The broker then manages the distribution of these messages to one or more consumers, which are responsible for processing them. This design promotes scalability, as producers can continue to generate messages without needing to know how or where it will be consumed, while consumers can focus on their processing tasks without worrying about message acquisition. It is commonly used in various distributed computing and messaging systems to optimize resource utilization and improve overall system performance. Using this architecture for a messaging system offers additional advantages, primarily because senders are not required to have knowledge of the consumers in the system. Furthermore, messages are buffered until consumers become available to process them.
Message Processing Guarantees
No Guarantee
In a system that provides no guarantees, there is uncertainty regarding the processing of any given message. It could be processed once, multiple times, or not at all. An example of such a scenario is illustrated below using Kafka.
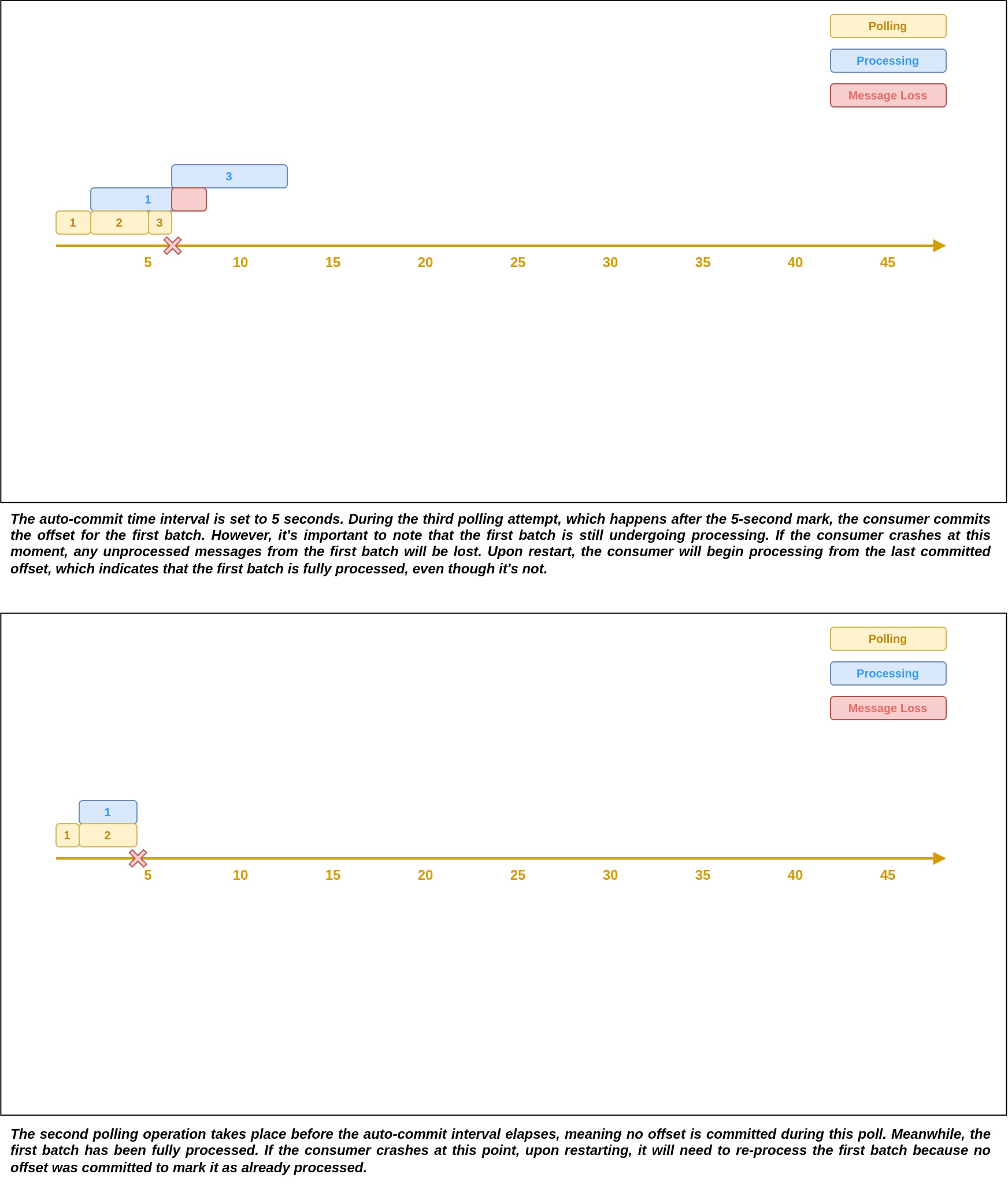
When employing Kafka's auto-commit feature and concurrently processing message batches, we may find ourselves in a situation with no guarantees. To elaborate, if we initiate a new batch polling immediately after receiving a batch, without first waiting for the previous batch to complete processing, we can end up in a scenario where no guarantees are provided. Auto-commit takes place after a set time interval when the consumer polls for a new batch of messages. If this interval elapses while the previous batch is still in the midst of processing, and the consumer subsequently polls for a new batch, the offsets are automatically committed. In the event that the consumer crashes at this juncture, any remaining unprocessed messages will be lost, as the consumer has already committed the offsets for the entire batch. If the batch is completely processed before the time interval elapses, and the consumer experiences a crash, the batch will be reprocessed once the consumer resumes, as it was unable to commit the offset.
At Most Once
In at most once setting, the system ensures that a message will either be processed once or not processed at all. A system with this processing guarantee suffers from message loss.

Consider a messaging system that utilizes Kafka for message passing. When offsets are manually committed immediately upon receiving a batch of messages, even before the entire batch has been fully processed, it leads to a scenario where at most once message delivery semantics are enforced. In the event of a consumer crash before all messages in the batch are fully processed, message loss occurs because the offset for the entire batch is committed prematurely. In the subsequent polling operation, a fresh batch of messages will be fetched from the broker, ensuring there is no redundant reprocessing of events. This trade-off prioritizes the avoidance of message reprocessing while accepting the potential loss of messages.
At Least Once
In at least once system, messages are guaranteed to be processed at least once, some messages can be processed multiple times.
Let's consider a Kafka system as an example, where offsets are automatically committed, and the consumer only requests a new batch of messages once it has successfully processed all the messages from the previous batch. This approach ensures that offsets are committed only after a batch has been successfully processed. In Kafka, the auto commit take effect when the consumer has polled for a new batch of messages after a configurable time has elapsed. Consumer polls before this time interval will not result in the committing of the offset. Now, imagine a scenario where the previous batch has been fully processed, but the system crashes before the automatic offset commit could occur. In this case, if the system were to recover and start processing again, it would reprocess the same batch. However, if the auto-commit was done successfully and there is any subsequent failure at this point, the previous batch will not be reprocessed, as its offset has already been committed. This helps to avoid duplicate processing of messages in the event of system failures.

By adopting a manual approach to offset commitment, we can also ensure an "at-least-once" processing guarantee. In this setup, offsets are committed only after the current batch of messages has been successfully processed. If a consumer experiences a failure during the processing of a batch, the offsets are not committed. Consequently, when the system resumes, it will reprocess the same batch of messages, avoiding potential data loss. In cases where a failure occurs immediately after we manually commit the offset, the consumer will fetch a new batch of messages from the broker upon recovery, ensuring that no messages are re-processed.
Exactly Once
Achieving exactly once delivery semantics in a messaging system is a challenging but highly desired goal. It guarantees that even in the face of retries due to failures, the message reaches the end consumer only once, eliminating both message loss and duplication. However, this gold standard of delivery guarantees is also the most complex to implement, demanding intricate collaboration between the messaging system and the applications responsible for creating and consuming messages. However, in 2017 Confluent introduced Exactly Once semantic in Apache Kafka 0.11. Read more about it here.
Idempotent Consumer
Opting for at least once delivery semantics is a solid choice in most use cases as it ensures the delivery of messages, even in the face of potential errors. However, this guarantee comes with a caveat—there's a chance of messages being delivered more than once due to these errors. The critical challenge here lies in the possibility of processing a message multiple times, which can introduce bugs into the system. To handle this problem, having an idempotent consumer becomes paramount. In essence, the consumer should be designed in such a way that processing the same message multiple times produces the same result as processing it once. Achieving idempotence can be approached by either making the operation itself idempotent or by implementing mechanisms to detect and discard duplicate messages, thus safeguarding the integrity and reliability of the system within the at least once delivery framework.
Order of Messages
In some systems driven by asynchronous messaging, the order of messages can be very crucial for maintaining system integrity and ensuring proper functioning. It dictates the sequence in which messages are processed, allowing data consistency across services. In scenarios where precise timing and coordination are essential, such as financial transactions or real-time data processing, maintaining a strict order is imperative. However, there are cases where relaxed message ordering can be acceptable. In systems designed for scalability and resilience, asynchronous event handling can sometimes tolerate out-of-order messages. When your system is susceptible to the impact of out-of-order messages, it is crucial to implement effective measures to mitigate this issue. You can find in-depth guidance on how to manage and address out-of-order messages here.
Resiliently Publishing Messages
In microservices using asynchronous messaging, resiliently publishing messages is crucial for maintaining data consistency across services. When updates to domain states are not atomically done with message publication, inconsistencies among services can occur. For instance, data may be updated successfully within a service, but if the subsequent message publish operation fails, other services might not be aware of the change, leading to data inconsistency between services. To address this challenge, the Transactional Outbox pattern is a valuable solution to ensure that data updates and message publishing are executed atomically, enhancing the reliability and integrity of microservices-based systems. You can learn more about the details about this pattern to implement it effectively and maintain data consistency between services.
Poison Messages
When a service encounters messages it cannot process due to unforeseen data or validation failures, the question of whether to ignore the event arises. In cases where the service's inability to process events is solely due to validation failures, it may be reasonable to ignore them. However, it's crucial to differentiate between this scenario and situations where the service fails due to bugs or unexpected data. In such cases, fixing the service and reprocessing the events by adjusting offsets is a viable solution. Additionally, implementing a dead letter queue is another option. When an message processing failure occurs, it can be routed to a dedicated queue for failed messages, allowing regular operations to continue uninterrupted. Subsequently, ad hoc processes or specific consumers can handle the reprocessing or requeuing of these mesasges as needed. In systems sensitive to out-of-order message processing, forwarding messages to a dead letter queue has the potential to disrupt the original message sequence. Hence, it's imperative to approach this situation with careful consideration and deliberate planning when designing the workflow.
Message Queue Implementations
When considering message queue implementations for our application, it's essential to leverage existing solutions rather than reinventing the wheel. Options like Apache Kafka, RabbitMQ, ActiveMQ, and many others offer battle tested message queue solutions. There are a few factors to consider when choosing which implementation to use for our use case. These factors include supported programming languages, messaging ordering, delivery guarantees, persistence, durability, scalability, latency, message channel capabilities, and the choice between self-hosted or cloud-managed services. Evaluating and selecting an existing message queue system that aligns with your specific requirements can significantly expedite development while benefiting from the wealth of features and optimizations these mature platforms provide, ensuring robust and efficient message communication in our architecture.
Eventual Consistency
Asynchronous communication can lead to a system becoming eventually consistent because it allows different parts of the system to operate independently and at their own pace. Imagine a scenario where one component updates data and another reads it. In an asynchronous setup, the update may not be immediately visible to the reader, leading to a temporary inconsistency. However, over time, as messages propagate and get processed, the system tends to converge towards a consistent state. This eventual consistency is a trade-off that allows for greater scalability and fault tolerance, as systems can continue working even when messages arrive after some delay.
Before implementing such a system, it's crucial to confirm with the business stakeholders, as they need to be aware of how data consistency may temporarily vary. This understanding ensures that users are prepared for potential discrepancies in data access or updates, especially in scenarios where rapid consistency is not guaranteed. Over time, as messages propagate and get processed, the system tends to converge towards a consistent state, but users' expectations must align with this inherent characteristic.
In summary, asynchronous communication in microservices offers the benefits of scalability, resilience, and loose coupling. However, it poses challenges related to eventual consistency, message ordering, implementation complexity etc. Careful implementation and a thorough understanding of the system's requirements are essential to harness the advantages while addressing these challenges effectively, ensuring a robust and responsive microservices architecture.
Explore More
Topics
Are you new? Start here
Microservice Architecture
Patterns & best practices to achieve scalability, flexibility, and resiliency.
Event Driven Architecture
Embrace Scalable, Responsive, and Resilient Systems through Event-Driven Paradigm.
System Design
Explore modern software solutions to scale to the horizon.