Events serve as the communication channel through which changes in one microservice are communicated to various other microservices within a system. Making sure that events are sent and received in a proper manner is really important to keep the whole event-driven system consistent. However, when events arrive in a different order than expected, it creates a big challenge for the system to stay consistent. Out-of-order events can lead to data inconsistencies in different services that last indefinitely. This corrupted data can then cause errors in operations that rely on it. In the worst cases, this issue can set off a chain reaction, where a single out-of-order event messes up the data flow, causing inconsistencies in different parts of the system and making the system's reliability go down.
Ways Out-of-Order Events Can Affect an Event Driven System
In a single server setup, inconsistencies can arise due to concurrency, where multiple similar operations run in parallel across multiple threads. In contrast, within a distributed system, the potential for data inconsistencies is significantly broader due to factors such as retries stemming from transient errors, network latency and the presence of multiple servers. Consequently, a distributed system is considerably more susceptible to experiencing data inconsistencies due to the interplay of resiliency mechanisms and race conditions.
Out-of-Order Arrival
Events can be processed out of order by consumers when the event stream itself is not properly sequenced. This situation occurs when, for some reason, events arrive at the message queue in an out-of-order manner. As a result of this, the events are subsequently delivered out of order to consumers who are expecting a well-ordered event stream. Lets look at how the out-of-order arrival of events can occur.
Multiple Producers
Services are often configured to automatically scale in response to increased loads. When a service undergoes scaling up to have multiple instances, each producer of an instance might simultaneously attempt to send its batch to the message queue, introducing a potential race condition. The initial batch to reach the message queue could include events that occurred later, while subsequent batches might contain events that happened earlier. This dynamic can lead to a situation where older events are positioned after more recent ones, potentially causing a chronological misalignment.
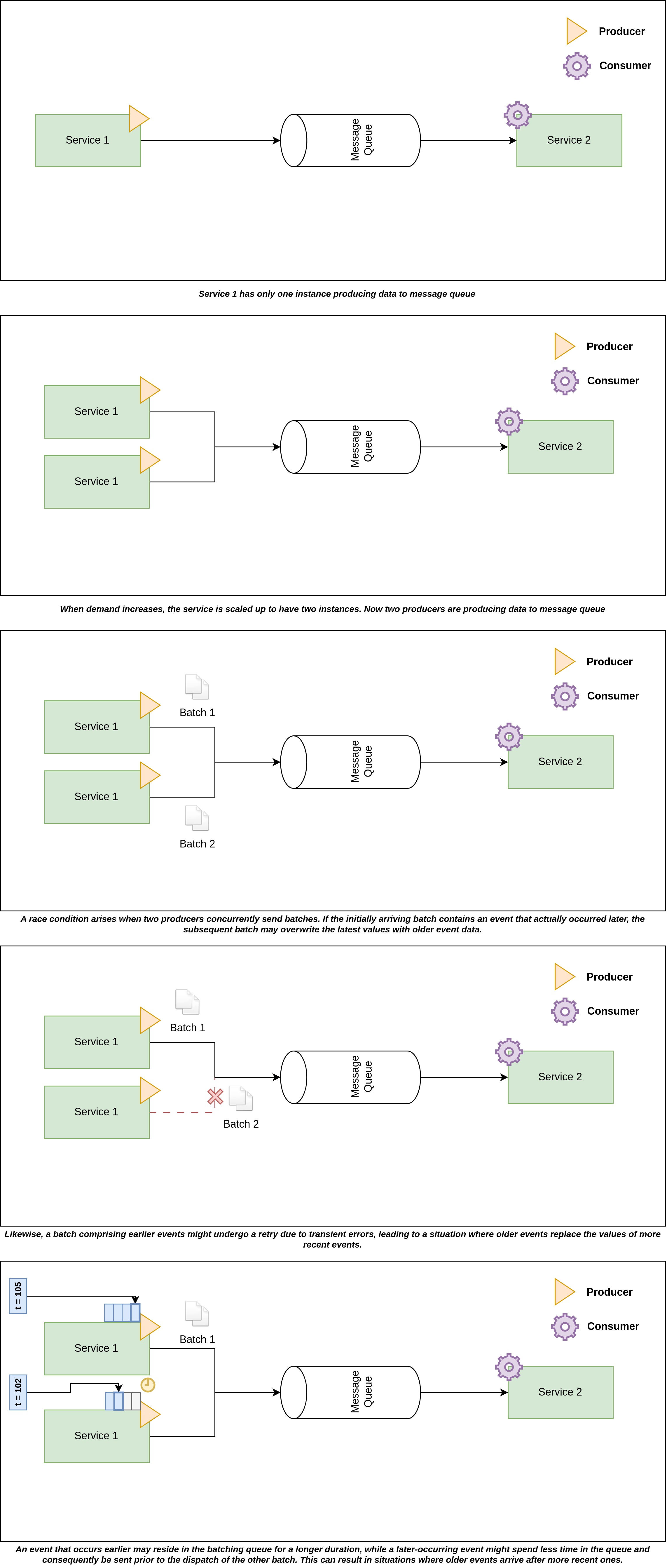
In another potential situation, a batch containing earlier events is sent first but faces a transient error. Meanwhile, a different batch from another producer is sent successfully. Eventually, the first batch is retried and successfully reaches the message queue. As a consequence, events arrive out of order within the message queue.
Another potential factor leading to out-of-order event arrival is the result of how producers batch their events. In specific message queue implementations, producers gather events into batches before transmitting them to the message queue, aiming to enhance throughput. Producers can either accumulate messages for a set duration or wait for a specified number of messages before dispatching the batch to the message queue. Depending on the state of the buffer or the time window for waiting, a batch containing the most recent events might be sent ahead of another batch containing older events, as depicted in the provided image. Such scenarios can disrupt the chronological order of events within the message queue.
Multiple In Flight Connections
The out-of-order arrival of events can also be influenced by how many in-flight connections are being used. Kafka producers allows this behavior to be configured. In other words, this property means the maximum number of batches that can be sent without waiting for acknowledgements to be received at any given time. When this parameter is set to a value greater than one, it enables the producer to send multiple messages before receiving acknowledgments.
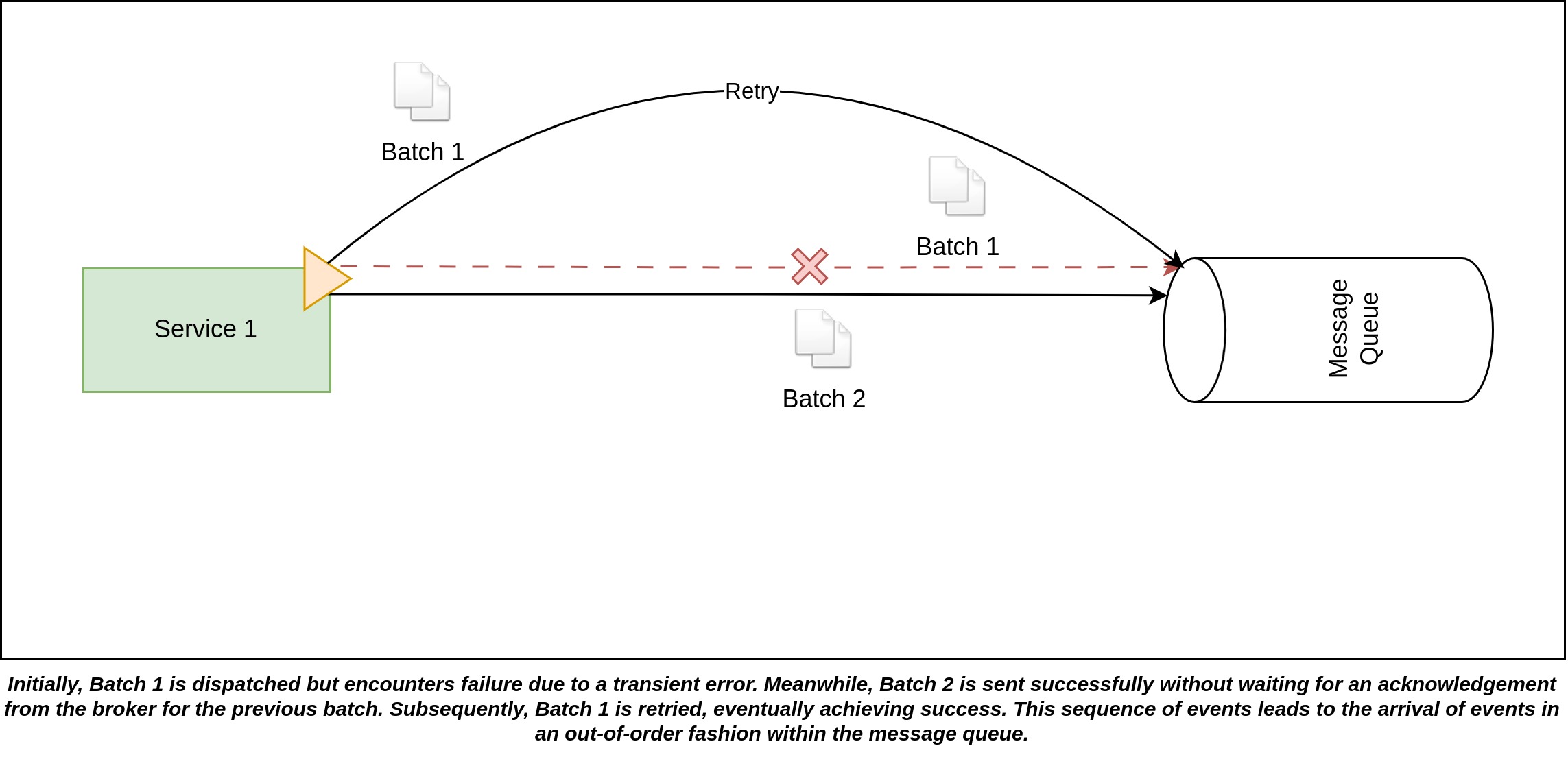
In the depicted scenario, with a maximum of 2 in-flight connections configured, Batch 1 is initially dispatched, followed by Batch 2. If Batch 1 encounters failure, the producer will initiate a retry for Batch 1. However, as another batch can be sent without acknowledgement for Batch, Batch 2 is sent and successfully recorded in the message queue. Subsequently, the producer retries Batch 1 and successfully writes it to the message queue. At this point, a noticeable issue arises: due to the asynchronous nature of retries and the absence of acknowledgment dependencies, the original order is compromised. As a result, the events within the message queue are arranged in an incorrect sequence.
Out-of-Order Delivery
Certain message queue implementations operate by delivering events individually, not in batches. Multiple consumers can concurrently extract data from this common source. Even if an event is in flight without acknowledgment, the message queue can still dispatch additional events provided that other consumers are available. This setup creates a context where race conditions can manifest. Moreover, strategies used to enhance system resiliency, like the retry mechanisms, can also play a role in triggering out-of-order message delivery scenarios.
Examine the illustrated example depicting how out-of-order delivery can occur as a consequence of transient errors and subsequent message queue retries.
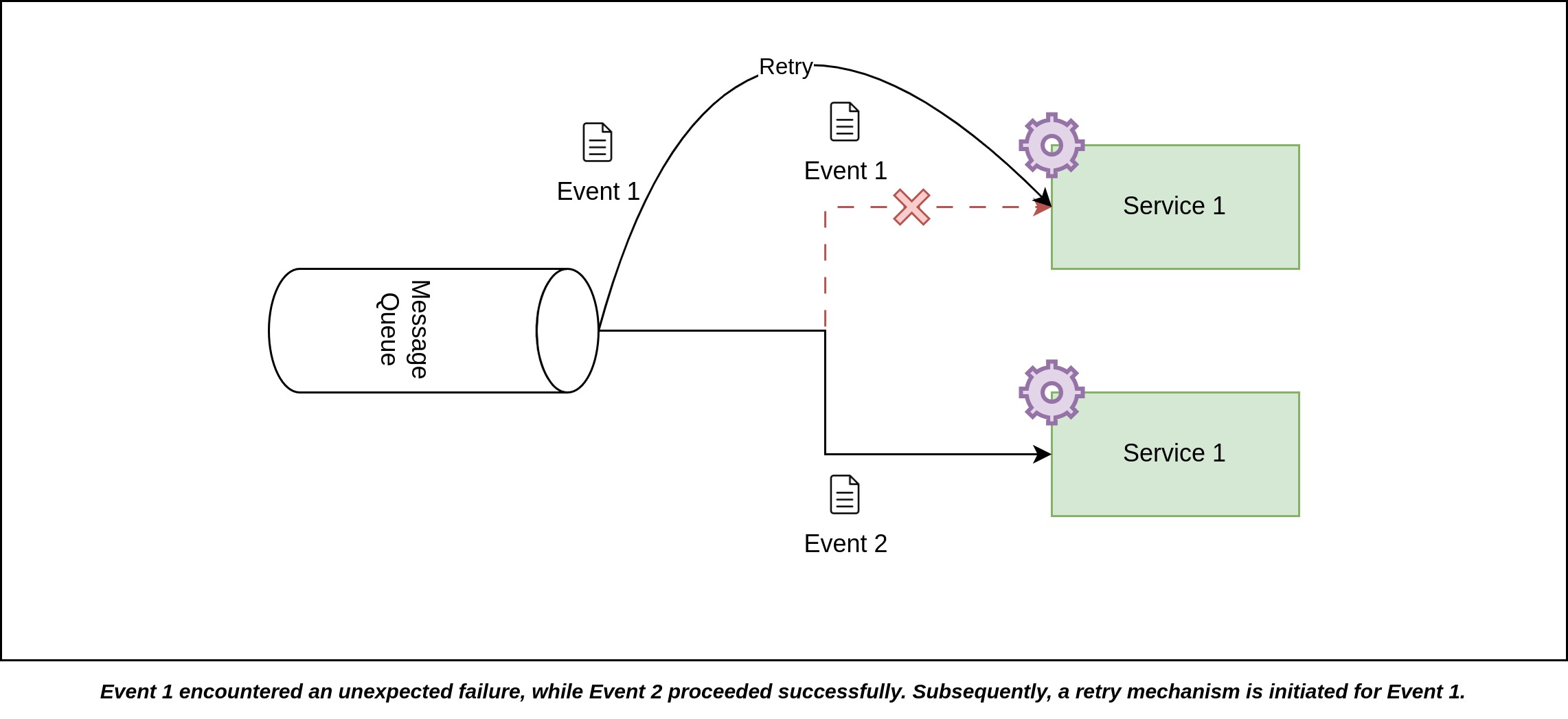
Initially, Event 1 is dispatched to the first instance of Service 1, closely followed by the transmission of Event 2 to the second instance of Service 1. However, Event 1 encounters a failure, resulting in a lack of acknowledgment. Meanwhile, Event 2 is processed successfully, and its acknowledgment is received. With the acknowledgment for Event 1 still pending after a certain amount of time, the message queue initiates a retry to transmit Event 1, which is accomplished successfully this time. Consequently, the order of events becomes disrupted: Event 2 is recorded in the service before Event 1, leading to an out-of-order event sequence.
Now, let's explore another example where events might be delivered out of order due to the emergence of race conditions.
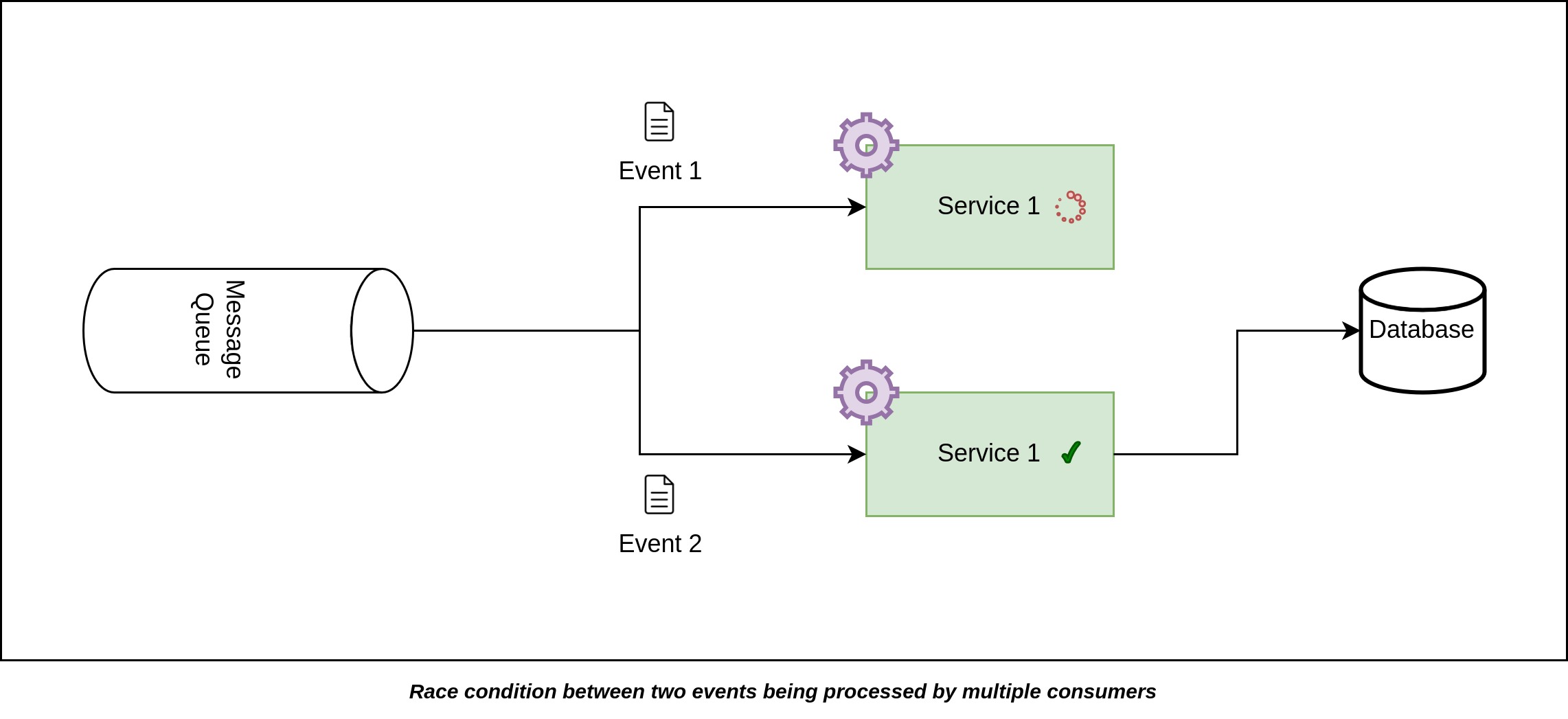
Event 1 and Event 2 are transmitted nearly simultaneously to the two separate instances of Service 1. However, depending on different network factors, Event 2 might arrive and get processed at the server before Event 1. Moreover, two events might have different processing steps depending on the types of the events. Even if the two events are of the same type and has the same processing operations, the data they carry will probably be different, leading to variations in how long it takes to retrieve and handle that data. Since different instances or threads execute operations at slightly different speeds due to factors like data differences and hardware variations, consuming both events at once can occasionally cause one consumer to finish processing a more recent event before the other instance finish processing an older event. As a result, Event 2 could be processed ahead of Event 1, causing a disruption in the sequence of events.
Handling Concurrency By Design
As previously highlighted, many challenges concerning event order comes from issues related to concurrency. Mitigating these problems could involve minimizing the presence of concurrency within our system, resulting in fewer ordering complications. Rather than relying on application code to explicitly manage these challenges, it's much better to architect the system in a way that naturally reduces concurrency. In this section, we will discuss how to handle concurrency through deliberate design choices.
Ensuring In Order Arrival of Events
The initial step to ensure event processing in the right sequence is to guarantee that events within the message queue are correctly ordered. As we discussed earlier, events might become out of order due to multiple producers sending messages to the same topic or using multiple in-flight connections to transmit message batches without waiting for acknowledgment even with a single producer. Let's break down how to tackle each of these problems.
One Producer Publishing Events
We need to architect the system to ensure that only one producer is publishing events to the message queue. As previously mentioned, when we position the producer within a service, the number of producers can increase as the instances of the service goes up due to scale up to address greater demand. To address this, the Transactional Outbox Pattern can be used. Employing this pattern is beneficial not only for enhancing system consistency but also for managing producer count.
With this method, events are written to an outbox table as part of a transaction. Subsequently, these events are asynchronously attempted to be published from the outbox table. By adopting this approach, all service instances write events to the outbox table, and a single producer is designated to publish events to the message queue. By ensuring only one producer operates, the likelihood of events arriving out of order in the message queue is significantly reduced.
There are two methods for achieving this. The first approach involves running a separate process that continually checks for unpublished events in the outbox table and then sends them to the message queue. The second method is to employ Change Data Capture technique, which automatically generates events whenever new events are added to the outbox table. If possible, configure the producer to operate in an idempotent manner and restrict it to using a single in-flight connection only. This ensures ordered arrival of events to the message queue.
For example, If we use Change Data Capture technique using Kafka Debezium Connector we can add the following properties to enable idempotence and allow only single in-flight request:
"producer.max.in.flight.requests.per.connection": 1,
"producer.enable.idempotence": true
However, it's important to note that restricting the number of in-flight requests per connection to just one can significantly reduce throughput. Therefore, this approach should be selectively applied in systems where maintaining strict event order is paramount for ensuring data consistency.
Allowing One In-Flight Connection Without Acknowledgement
Another situation leading to out-of-order event arrival is when multiple in-flight connections are permitted without waiting for acknowledgment. If one of these connections encounters failure and initiates a retry, the sequence of events can be disrupted. To counter this, it's recommended to restrict the system to one in-flight connection at a time. Before sending a new batch of messages, acknowledgment for the ongoing in-flight message must be received from the message queue. This approach guarantees the order of messages in the message queue, reducing the likelihood of events arriving out of order.
Key Based Routing to Partition
Key-based routing to partition is a technique employed in message queues to ensure optimal partitioning of events. This approach involves assigning events to specific partitions based on their keys. The fundamental idea behind this strategy is to use the key value to determine which partition the event should be directed to. Events that have the same key value are always directed to the same partition.
In the context of microservices, we often use events to share database updates between different services. What we really want is to make sure that events coming from the same row of a particular table are always processed in the right order. To make sure these events are processed in the right order, we can rely on something called an "event key." Essentially, we use the primary key of the table as event key. What happens then is that events that have the same key, which are generated from the same row of the table, always end up together in one partition, ensuring they're processed in the order they were created. Notably , some message queue systems like Kafka makes sure that this order is maintained in a partition. Therefore, if we must make sure that a set of events is processed in the exact order they're generated, we must route them to the same partition. For that it's essential to assign them the same value as key. This key ensures that these events are directed to the same partition, maintaining their sequence.
You might wonder why we go through the trouble of partitioning events. Why not just have one partition for each topic and consume from there? While this approach indeed maintains order across all events, it's important to note that we often don't require order among all events. More frequently, what matters is ensuring related events are processed in sequence. This is where the concept of partitioning comes into play. By dividing a topic into multiple partitions, we can enhance parallelism. Events that aren't related can be processed concurrently without any issues, all while preserving the order of those that are related.
Consuming Events Serially From Individual Partition
When services subscribe to a topic, they must do so as part of a consumer group. This setup ensures that consumers within the same group read from the topic collectively. In this scheme, each partition is exclusively consumed by a single consumer, while a consumer can simultaneously read from multiple partitions. By preventing multiple consumers from accessing the same partition, this arrangement eliminates potential concurrency issues for events that are related.
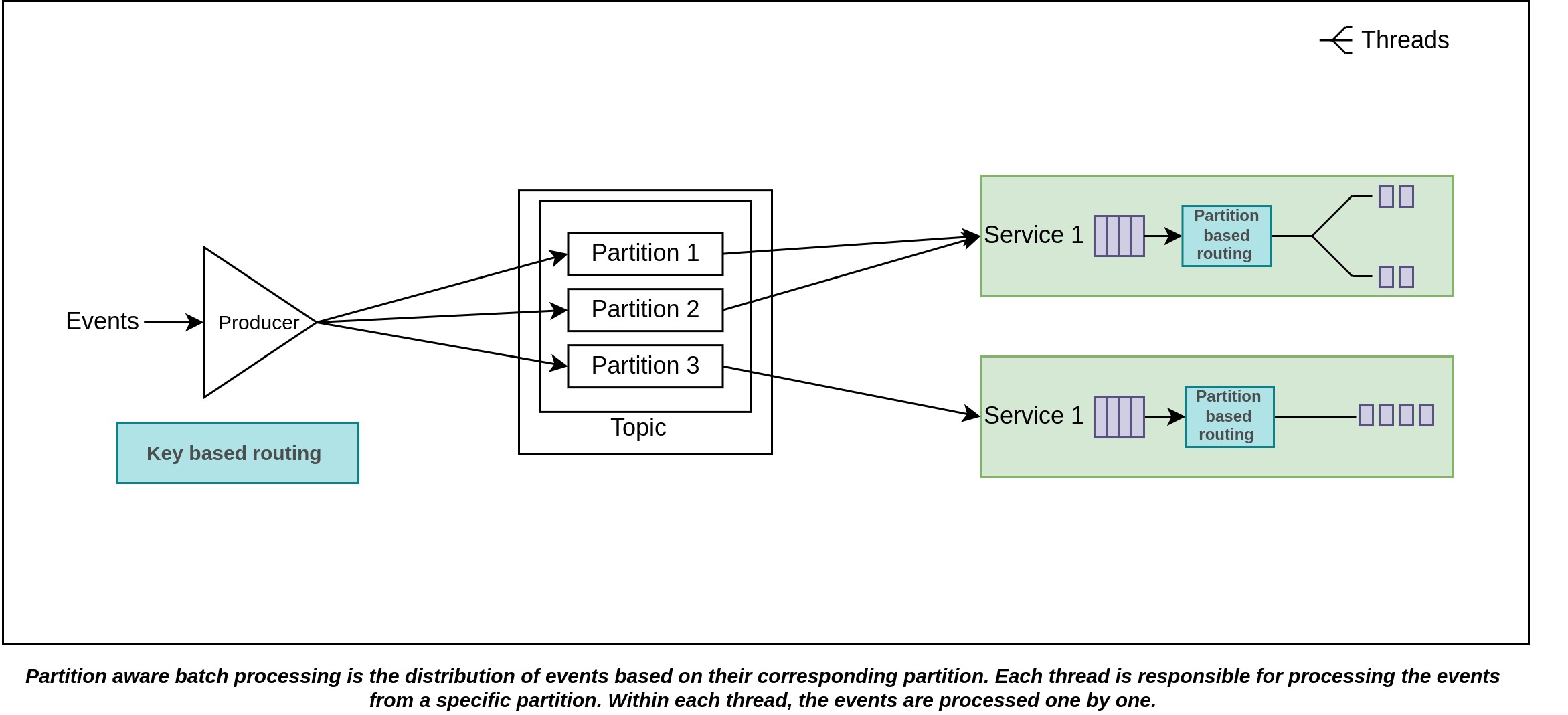
As we previously discussed, a consumer can read from many partitions. To further optimize our process, we can introduce partition-aware batch processing, allowing events from different partitions to be handled in parallel. This approach involves grouping events based on their assigned partitions and processing each group concurrently. Since events from separate partitions are independent of each other, there's no concern regarding their parallel processing.
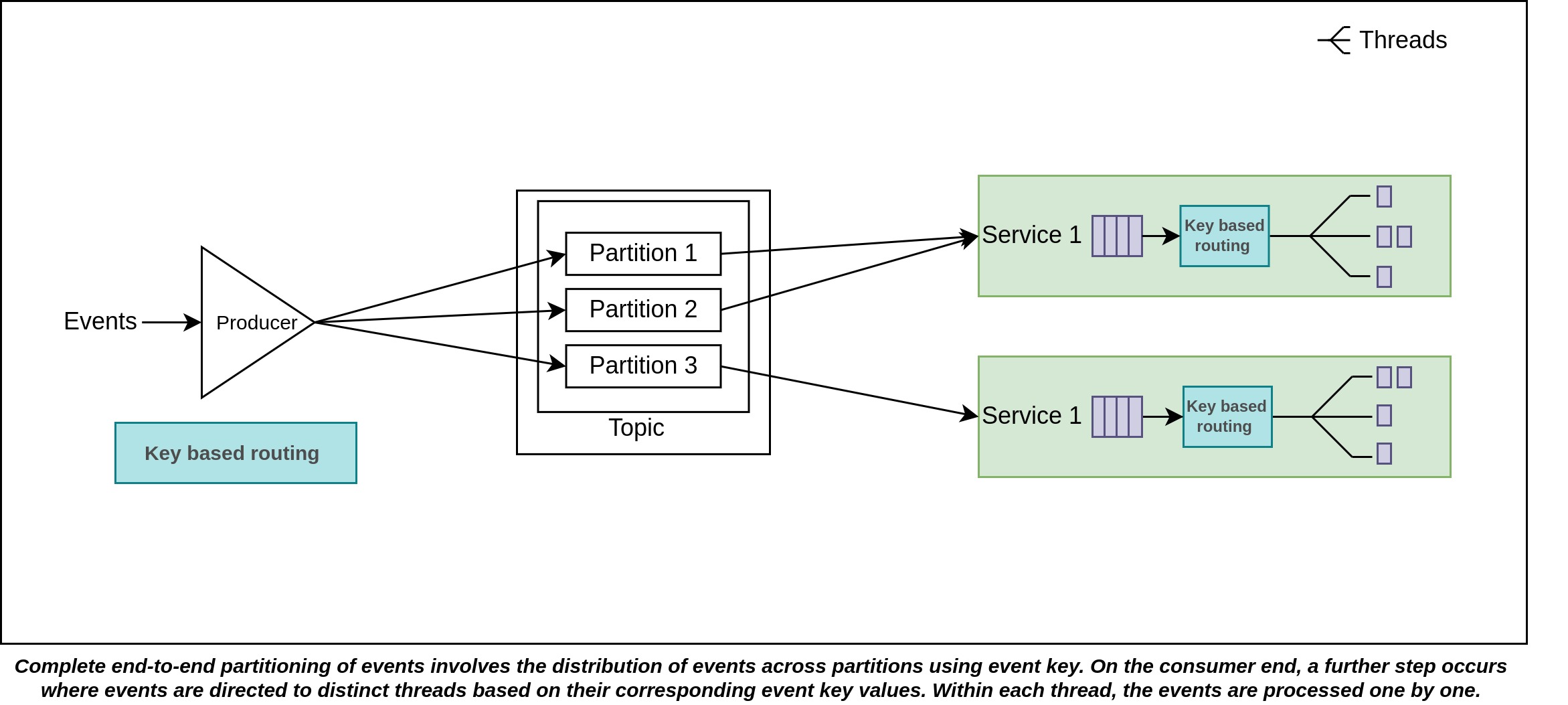
For increased parallelism, an alternative approach involves skipping the earlier optimization and instead, re-partitioning batched events based on their keys. This approach directs the events onto multiple thread paths. Events within the same thread path are processed sequentially, while different threads operate in parallel to one another. Opting for a higher thread count can yield a greater degree of parallelism. This tactic is particularly useful when each consumer generally accesses a low number of partitions on average.
How Failures Are Handled
The proposed design effectively addresses the issue of concurrency, a primary cause of out-of-order event processing. However, it's important to acknowledge another potential source of out-of-order processing: the resilience mechanism of retrying. To ensure the robustness of this design, it's recommended to incorporate a message queue, such as Kafka in which consumers can pull a batch of events and commit the offset once the entire batch has been successfully processed. The client for the message queue on the consumer side will not pull a new batch until the current batch is processed and the offset is committed. This approach is crucial for maintaining the order of events.
If the processing of an individual event encounters failure, the entire batch of events will undergo a retry process. During this retry, the batch is subjected once again to the consumer-side partitioning and processing flow, following the same path as the initial processing attempt. It's important to note that this retry approach involves exclusively reprocessing the failed batch itself, without trying to process another batch in parallel.
This handling of retries ensures the preservation of the original order of events. By concentrating exclusively on rectifying the failed batch without interleaving it with other batches, the design effectively maintains the chronological sequence of events intact. However, this approach requires that the consumers are idempotent. This is due to the nature of the message queue, which ensures at least once delivery guarantee. In cases where a batch fails and is retried, it's possible that certain events within that batch could end up being processed multiple times. Therefore, it becomes crucial for the consumer to either have idempotent processing logic (meaning that processing an event multiple times has the same outcome as processing it once) or the capability to recognize and handle duplicate events effectively.
Here's an example code snippet that demonstrates how we can implement this approach using the KafkaJS client in JavaScript:
async function eachBatchHandlerWithKeyBasedPartition({ batch, resolveOffset, heartbeat, isRunning, isStale }) {
const smallestOffset = +batch.messages[0].offset;
let processedUntilIndex = 0;
const processedList = [];
const partitions = Array.from({ length: numberOfKeyBasedPartition }, () => []);
for (let message of batch.messages) {
let { key } = message;
const partitionIndex = hashStringToInt(key.toString(), numberOfKeyBasedPartition);
partitions[partitionIndex].push(message);
processedList.push(false);
}
const result = await Promise.allSettled(
partitions.map(async (partition) => {
for (let message of partition) {
if (!isRunning() || isStale()) break;
const callbackProps = {
topic: batch.topic,
partition: batch.partition,
message,
heartbeat,
offset: message.offset
};
await handleOnMessage(callbackProps);
const positionInBatch = message.offset - smallestOffset;
processedList[positionInBatch] = true;
if (positionInBatch === processedUntilIndex) {
while (processedList[processedUntilIndex]) ++processedUntilIndex;
resolveOffset(smallestOffset + processedUntilIndex - 1);
}
await heartbeat();
}
})
);
for (const res of result) if (res.status === "rejected") throw res.reason;
}
await this._consumer.run({
eachBatchAutoResolve: false,
eachBatch: eachBatchHandlerWithKeyBasedPartition
});
For every batch of events received, the function eachBatchHandlerWithKeyBasedPartition will be called. This function is responsible for dividing the events within the batch into multiple groups. These groups are then processed concurrently. Inside each group, the events are handled sequentially, one after the other.
As soon as the function detects a sequence of successfully processed events starting from the beginning of the batch, it will mark that point and commit the offset. This ensures that up to that point, the events have been reliably processed and won't be reprocessed if a retry occurs.
If a failure occurs following such a successful commit, in subsequent retry attempts, the events that had already been successfully committed will not be included in the batch being retried. This approach is designed to minimize the occurrence of duplicate event processing as much as possible. By excluding the events that have already been reliably processed and committed, this mechanism effectively enhances performance while upholding the integrity of event order.
Handling Concurrency By Implementation
When resolving concurrency through design is not feasible, applications need to employ strategies to mitigate the occurrence of out-of-order events. Here are several such strategies:
Versioning
One effective strategy for addressing out-of-order events is by implementing versioning mechanisms. In this approach, each database table has a version column that is incremented whenever the row undergoes modifications. This version information is then associated with the corresponding event generated for that row. The key to ensuring event order is to compare the incoming event's version with the current version in the consuming service. When an event arrives with a version that is only one increment higher than the current version, the event is processed and acknowledged. This validation step prevents the processing of events with versions that significantly deviate from the expected progression, consequently averting the potential disruptions caused by out-of-order events.
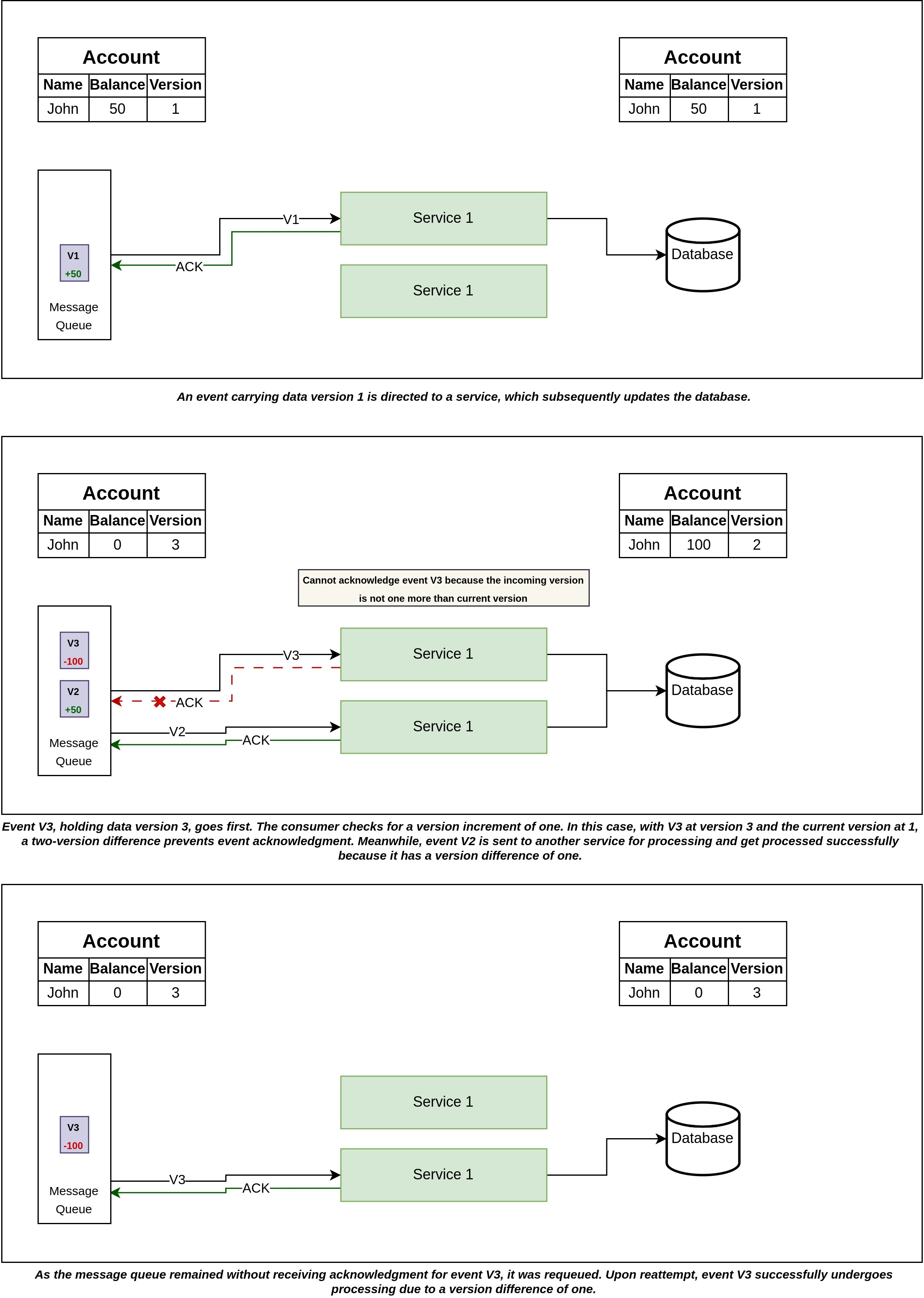
Take a look at the above image, which illustrates a practical example of how to tackle the issue of out-of-order events through versioning. The concept is depicted visually, making it easier to understand how this strategy works in practice.
This approach is particularly effective when dealing with events that involve partial updates. In events containing partial updates, only the fields that have been modified are included, and these updates collectively contribute to the creation of the most current state. To ensure the integrity of the data, it's crucial that all events are processed and they are processed in the correct sequence. Consecutive version numbers serve as a comprehensive tracking mechanism, allowing us to keep a track of every version. They act as checkpoints that help us identify if any versions have been missed in the sequence.
Should we encounter a scenario where a version is missing, it triggers a specific response. In this case, the received version is not acknowledged. The message queue then re-queues the event to be retried after not receiving any acknowledgment from the consumer. Meanwhile the consuming service wait for the missing version to be received, and upon its arrival, it is processed and acknowledgement is sent for it. As a result, not only is the event with the missing version successfully processed, but the initial retried event also goes through the necessary processing steps later, leading to a comprehensive and accurate event processing flow.
When an event comprises the entire state of a database row, it becomes possible to skip versions when we receive an event with a higher version number than the one we were expecting. For example, imagine a situation where an event with version v3 arrives, yet the consuming service has only encountered data corresponding to version v1. In this scenario, version v3 can be applied effectively, even without the previous application of version v2. As version v2 eventually arrives, it enables us to bypass the associated processing step. Instead, we can directly acknowledge version v2. This optimizes the event processing flow by allowing later versions to supersede the requirement for intermediate versions.
Timestamp
Another strategy for mitigating out-of-order events involves using event timestamps. This approach capitalizes on the temporal information associated with each event. While relying on event timestamps is theoretically advantageous, achieving precise time synchronization across various service instances can be challenging as two different machines on the network cannot have hundred percent time accuracy. However, we can achieve very close accuracy using network time protocol (NTP), which is suitable for many use cases. Another approach to generating event timestamps involves utilizing the database-generated row updated time. This mechanism relies on a database trigger that automatically updates the "updated time" column after each modification. By leveraging this value as the event timestamp, we can capture the precise time at which changes were made to the data and as this is generated in a centralized database the time synchronization issue can be averted. This approach offers a reliable and accurate way to establish the timing of events, ensuring that the event sequence aligns closely with the chronological order of data modifications in the database.
The underlying principle of this strategy is similar to versioning: events arriving with timestamps greater than those previously applied will be processed. Conversely, events with older timestamps are acknowledged without being processed.
It's important to note that this method may encounter limitations when dealing with events involving partial update states. In such cases, as the timestamps aren't consecutive, there's no reliable means of tracking missed events and thus it is very difficult to process all events in order. This approach is best suited for events containing complete data states. Intermediate events can be skipped when an event with a higher timestamp arrives, provided that the events contain the complete state.
Addressing the challenge of out-of-order events is a very critical thing to do when an event-driven system needs accurate ordering to maintain consistent states across services. This challenge frequently stems from concurrency and the retry-based resilience mechanism. As we've explored, while mitigation techniques exist, the foremost solution is to proactively design the system to avoid concurrency rather than to write application code to handle it by implementations. By architecting systems with concurrency in mind and integrating mechanisms to tackle event reprocessing, the complexities of out-of-order events can be not only managed but substantially mitigated, thereby fortifying the reliability and integrity of event-driven systems.
Explore More
Topics
Are you new? Start here
Microservice Architecture
Patterns & best practices to achieve scalability, flexibility, and resiliency.
Event Driven Architecture
Embrace Scalable, Responsive, and Resilient Systems through Event-Driven Paradigm.
System Design
Explore modern software solutions to scale to the horizon.