Microservices applications are more vulnerable to security threats compared to monolithic applications because they have a larger attack surface. In a microservices architecture, the application is made up of many individual services that communicate with each other over a network. This means there are numerous entry points for potential security breaches, whereas a traditional monolithic application has only one entry point. Since these services communicate over a network, there are specific security concerns to address, such as preventing spoofing (fake identity), eavesdropping (unauthorized listening), and data modification during transmission. This is unlike the inherent security provided by in-process communication in monolithic applications. To ensure the security of a microservices system, it's essential to carefully consider and address all these factors.
Security Principles
Principle of Least Privilege
When granting access to someone, it's important to give them only the permissions they absolutely need to perform a specific task. Moreover, this access should have a time limit, meaning it's only valid for the duration required to complete that task. This approach ensures that if the access somehow falls into the wrong hands, the potential attacker will have very limited access to the system and for only a short period of time.
Defense In Depth
Castles are great examples of defense in depth in practice. Just as castles employed multiple defensive mechanisms to protect against invaders, modern cyber-security adopts a similar approach. In a castle, there were outer walls, moats, drawbridges, and inner fortifications. Similarly, in cyber-security, layers of security measures like firewalls, intrusion detection systems, encryption, access controls, and regular software updates are implemented. Each layer adds an extra barrier, so even if one layer is breached, there are others to deter or stop potential attackers.
In a microservices architecture, one way to enhance security is by keeping the microservices within a private network, which means they are not directly accessible from the public internet. Instead, we can utilize an API gateway as a sort of entry point to expose only the necessary APIs to the public. Additionally, to protect data while it's being transferred between these microservices, we can employ security mechanisms like TLS or mTLS. This ensures that even within the private network, the data remains secure from eavesdropping or tampering. To add an extra layer of security, access control systems can be implemented to ensure that only authorized microservices are allowed to communicate with each other, preventing any unauthorized access.
Build Security Into Delivery Process
The traditional approach of treating security as an afterthought doesn't work well in the context of microservices because it exposes a broader attack surface with numerous security considerations. Securing a large number of services can be overwhelming, so it's crucial to foster a culture where developers have a solid understanding of security concerns. Instead of involving security specialists only after the application is built, developers and security experts should collaborate during the development process. This means actively reviewing and addressing security issues in the code. Additionally, it's essential to regularly scan code and dependencies for vulnerabilities. Automated tools like the Zed Attack Proxy (ZAP), which simulates malicious attacks, can help identify vulnerabilities. There are also static analysis tools like Brakeman for Ruby and services like Snyk that can spot potential security weaknesses, including vulnerabilities in third-party libraries. Integrating these tools into our continuous integration (CI) process and standard check-ins is a proactive approach to building secure microservices.
Key Security Fundamentals
Authentication
Authentication is the process of confirming the identity of the party that wants to access our system. This party can be either a system, like a microservice, or a human user acting via a client application. The choice of authentication method depends on who's trying to access our system. For instance, if a system is accessing other systems on behalf of a user, the user typically grants it permission first. In such cases, we often use OAuth 2.0 as the authentication mechanism. On the other hand, when it's a human user trying to access the system, we typically use a combination of a username and password, and sometimes an additional authentication factor for added security.
Authorization
Authorization defines what actions a user, who has already been authenticated, is allowed to take within the system. Without proper authorization controls, an authenticated user could potentially have unrestricted access to the system, which is a security risk. Authorization is what sets boundaries on a user's actions, specifying what they are permitted to do and what they are not. In a typical microservices setup, authorization can occur at two levels: the API Gateway and at each individual service level. Authorization at the gateway level tends to be more general and overarching, while authorization at the service level is more specific and fine grained, allowing for a more detailed control over user actions.
Data Confidentiality
Data Confidentiality is a security concept focused on protecting sensitive information from falling into the wrong hands. It addresses various scenarios, such as intercepting data during transmission and safeguarding data when it's stored. When data is in transit, it's crucial to secure it to prevent unauthorized individuals from intercepting and viewing it. This involves employing encryption methods that ensure data remains confidential and cannot be accessed by potential eavesdroppers or "man in the middle" attackers.
Moreover, data at rest, whether it's stored in a database or on disk, should also be encrypted. Database encryption operates at the database level, ensuring that even if someone gains access to the database, they can't decipher the stored data without the proper decryption keys. Disk-level encryption, implemented at the operating system level, secures data on storage devices, making it indecipherable if the physical media is stolen or compromised. Additionally, application-level encryption involves encrypting data before it's written to the file system or database, adding an extra layer of protection to sensitive information. Altogether, these measures work in harmony to maintain the confidentiality of data both during transmission and when it's at rest.
Data Integrity
A potential threat is that an unauthorized party could intercept communication and manipulate the data to their advantage. Systems designed with integrity in mind take this into account and implement safeguards to allow the recipient to detect and reject modified requests. One common method to ensure the integrity of a message is by digitally signing it. For instance, when data travels over a secure channel like Transport Layer Security (TLS), it is automatically protected for integrity. If we use HTTPS for communication between microservices (which is essentially HTTP over TLS), our messages are also safeguarded for integrity while they're in transit. This means that any unauthorized alterations to the data can be detected and discarded.
Levels of Trust In Microservices: Implicit vs Zero Trust
In a microservices setup, numerous services are in constant communication through the network, which is quite different from how things worked in monolithic applications. This network-based communication introduces security challenges because data is traveling over potentially insecure channels. This leads to a crucial question: should we automatically trust everything within our network, even if it's a private one? In response to this question, two trust models have emerged: implicit trust and zero trust. These models address how we approach trust and security within a microservices architecture.
Implicit Trust
Traditionally, companies used to place their software and systems on a private network, protected by firewalls at the network's edge. The idea was simple: if someone is inside the company's network, he is considered trustworthy, and if he is outside, he is seen as potentially untrustworthy. This model worked fine in the past.
However, this approach becomes problematic when we have mobile employees, use cloud services, or need to collaborate with external partners. The problem then is that there are too much implicit trust. This implicit trust can be exploited by attackers. Once they breach the network's perimeter defenses, they can gain access to everything inside the network.
For instance, if a company uses VPNs (Virtual Private Networks) to connect remote workers to its network, all an attacker needs to do is steal a user's login credentials, and they can get inside the company's network without much difficulty. This highlights the vulnerability of the traditional approach to network security.
Zero Trust
With the rise of mobile devices and cloud computing, the way we think about security has changed. We used to focus on securing our networks, but now we need to make sure that anyone who needs access to our systems—whether they're employees, partners, contractors, or others—can do so securely, no matter where they are, what device they're using, or what network they're on. The problem is that the more people and devices we allow to access our systems from outside, the more opportunities there are for attackers to get in. If any of these external access points are compromised, it could put our entire network at risk. To address this new challenge a second mindset called Zero Trust has emerged.
Zero Trust is like a security mindset where we assume that everything is potentially dangerous, and we can't trust anything by default. This includes the systems we communicate with, the requests we receive from other systems, and even the data as it travels over the network. We don't rely on the idea of a safe perimeter or location. Instead, we take a lot of precautions to stay safe.
In the world of Zero Trust, we carefully check all incoming requests to see if client sending the requests can be trusted. We make sure that all data traveling between systems is encrypted so that no one can spy on it or tamper with it. We also make sure that any data stored on our systems is stored safely so that even if someone gets in, they can't easily access our sensitive information. Essentially, it's about being super cautious and not assuming anything is safe, no matter where it's coming from or going to.
Securing Data
Data In Transit
Identity of Server
One of the most important security concerns is that the server we are talking to is exactly who we think it is. Malicious actors can impersonate legitimate servers, intercepting sensitive information in the process. This is where technologies like Transport Layer Security (TLS) come into play. TLS helps establish and confirm the identity of the server we are trying to connect with, ensuring that we are communicating with the genuine server and not an imposter.
Identity of Client
Just as it's crucial to verify the identity of a server, confirming the identity of a client is equally important. This is because bad actors can pretend to be legitimate clients and send harmful requests to upstream services, gaining an unfair advantage. Occasionally, if a system's credentials are compromised, a malicious actor might pose as a client and attempt to access protected resources using those stolen credentials. In such cases, client identity becomes a second layer of security. If we can't confirm the identity of the requesting client, we reject the request. To tackle issues related to client identity, we can employ a technology called mTLS (mutual Transport Layer Security). Mutual TLS provides the same protection as TLS but goes a step further by also verifying the identity of the client, adding an extra layer of security to our communications.
Data Visibility
When data is sent from one service to another, there is a risk that a malicious party can intercept and view that data using a method called a "man-in-the-middle" attack. This means someone unauthorized could eavesdrop on our sensitive information as it travels between services. This is especially a concern when data is transmitted using the HTTP protocol because it's not inherently secure. However, if we use technologies like TLS or mTLS, it's like adding a protective shield around our data. These technologies ensure that our data remains private and cannot be viewed by anyone with malicious intent while it's in transit.
Data Integrity
When data is traveling between places, it's vulnerable to tampering by malicious parties if we don't take precautions. To prevent this, we use technologies like TLS or mTLS, which act like protective shields for our data, ensuring it can't be altered during transit. If someone does try to modify the data, the server on the other end can detect the changes and reject the request. Sometimes, though, we need to send data over less secure channels like HTTP. In such cases, we can use a method called hash-based message authentication code (HMAC). With HMAC, we create a hash and send it along with the data. When the recipient gets the data, they can check this code against the data to make sure it hasn't been tampered with.
Data At Rest
A lot of the major security breaches we hear about involve attackers getting hold of data that's just sitting there, not actively moving around. The problem is, this data is often in a form that the attacker can easily read. This happens when the data isn't encrypted or when the way it's protected has a big, fundamental flaw that the attacker can exploit. In simpler terms, it's like leaving a book out in the open for anyone to read, and sometimes even when we try to put it in a locked box, the box has a weak lock that can be easily picked.
It's crucial to keep our data safe by encrypting it. Regardless of the programming language we use, there are trustworthy and regularly updated versions of encryption methods that experts have reviewed and improved over time. When it comes to securing passwords, it's essential to use a technique called "salted password hashing." This method ensures that passwords are never stored in plain, easily readable text. Even if an attacker manages to crack one hashed password through brute force, they won't automatically gain access to other passwords because each one has its own unique protective layer (the "salt").
With the decreasing cost of storage, businesses have started to gather and store vast amounts of data for potential future use. However, a significant portion of this data can include sensitive information such as Personally Identifiable Information (PII), which relates to a person's identity. We have to handle this kind of data with the utmost care. Data like this can quickly become a liability, especially when it serves little or no purpose. When we collect data, it's wise to gather only the minimum amount necessary to meet our specific needs. If the data isn't there in the first place, it can't be stolen, and no one can request access to it, even government agencies. In essence, less data means fewer potential problems and risks.
When a database holds sensitive information, it's crucial to safeguard it through encryption. Certain databases offer built-in encryption features, like SQL Server's Transparent Data Encryption, which make the encryption process seamless and transparent. To manage the keys used for encryption, it's a good practice to employ a separate key vault. These key vault systems not only store the encryption keys securely but also manage their life cycle, including the ability to change them when needed. One particularly useful tool for this purpose is HashiCorp's Vault, which can efficiently handle key management and access control, ensuring the security of our sensitive data.
Creating backups is a smart practice to ensure data safety, especially for important information. It might sound like common sense, but if we consider certain data sensitive enough to warrant encryption in our active production system, it's equally important to encrypt any backups of that data. This additional security measure ensures that even if the backup falls into the wrong hands, the sensitive information remains protected.
Securing North/South Traffic
Microservices present a larger attack surface because business components have been broken down into multiple services. The first level of security that we can apply is to place all the services within a private network. This allows them to communicate with each other safely in the private network and expose only the necessary set of APIs to the public internet. Typically, this is achieved using an API gateway, which acts as a proxy for requests to the internal microservices. This arrangement keeps the microservices isolated from the unsecured public internet while still indirectly allowing users on the public internet to access various functionalities of the microservices. Consequently, the surface of attack is greatly reduced as the API Gateway becomes the only entry point of the microservices system.
The API Gateway being the only entry point has the responsibilities to screen all incoming requests for security concerns. It should reject requests at the gateway level that cannot be authenticated. So, the API Gateway has the responsibility to authenticate users requests. The gateway can implement other security related features such as rate limiting to prevent users from making an excessive number of requests that could potentially harm the performance of the microservice application.
Implementing security at the API Gateway level helps to separate security concerns from the internal microservices. This approach allows microservices to focus solely on their core business functions. Service-level developers can then concentrate on building these functions effectively without the added burden of implementing security measures. Combining security and business logic within each service can introduce unnecessary complexity and maintenance challenges. When a security measure, such as the authentication method, needs to change, it becomes necessary to update every service to reflect this change in security. Furthermore, in systems with services built using various programming languages, replicating the same security processes in different languages and ensuring accuracy in each implementation becomes a cumbersome task. Additionally, when services need to scale up due to increased demand, the number of connections to the authorization server can rise significantly with the growing number of service instances in the system. Therefore, implementing security at the edge, within the API Gateway, appears to be the most logical choice. This approach helps prevent coupling, duplication, and the associated maintenance overhead.
Authentication At Edge
Authentication is one of the security measures implemented at the API Gateway to verify the identity of the user making a request. To establish an effective authentication scheme, it's crucial to thoroughly understand our microservice's intended audience. Are human users accessing our microservice through a client application? Or is the microservice application accessed by other systems? Depending on the audiences of the system, we may need to implement or support different authentication methods.
One effective method for authenticating various systems is by utilizing certificates. In this approach, the API Gateway is configured to permit requests exclusively from clients possessing valid certificates. To achieve this type of authentication, Mutual Transport Layer Security (mTLS) can be implemented. With mTLS, the backend APIs are secured in a way that they only accept requests from clients holding certificates issued by a trusted certificate authority. For instance, Tesla relies on mTLS to establish secure connections between their vehicles and their backend services.
To authenticate human users, we can create a user service that stores user data and offers the capability to authenticate a user's identity. Once the user's identity is verified, this service can issue an authentication token. Alternatively, we can opt for an existing off-the-shelf solution that implements the standard OpenID Connect (an extension of OAuth 2.0). This approach saves us from the need to build our own identity provider, leveraging established solutions instead of reinventing the wheel.
Organizations can deploy an existing OpenID Connect platform on their private network. To enable user authentication with the authorization server, they should expose the authorization endpoint through the API Gateway.
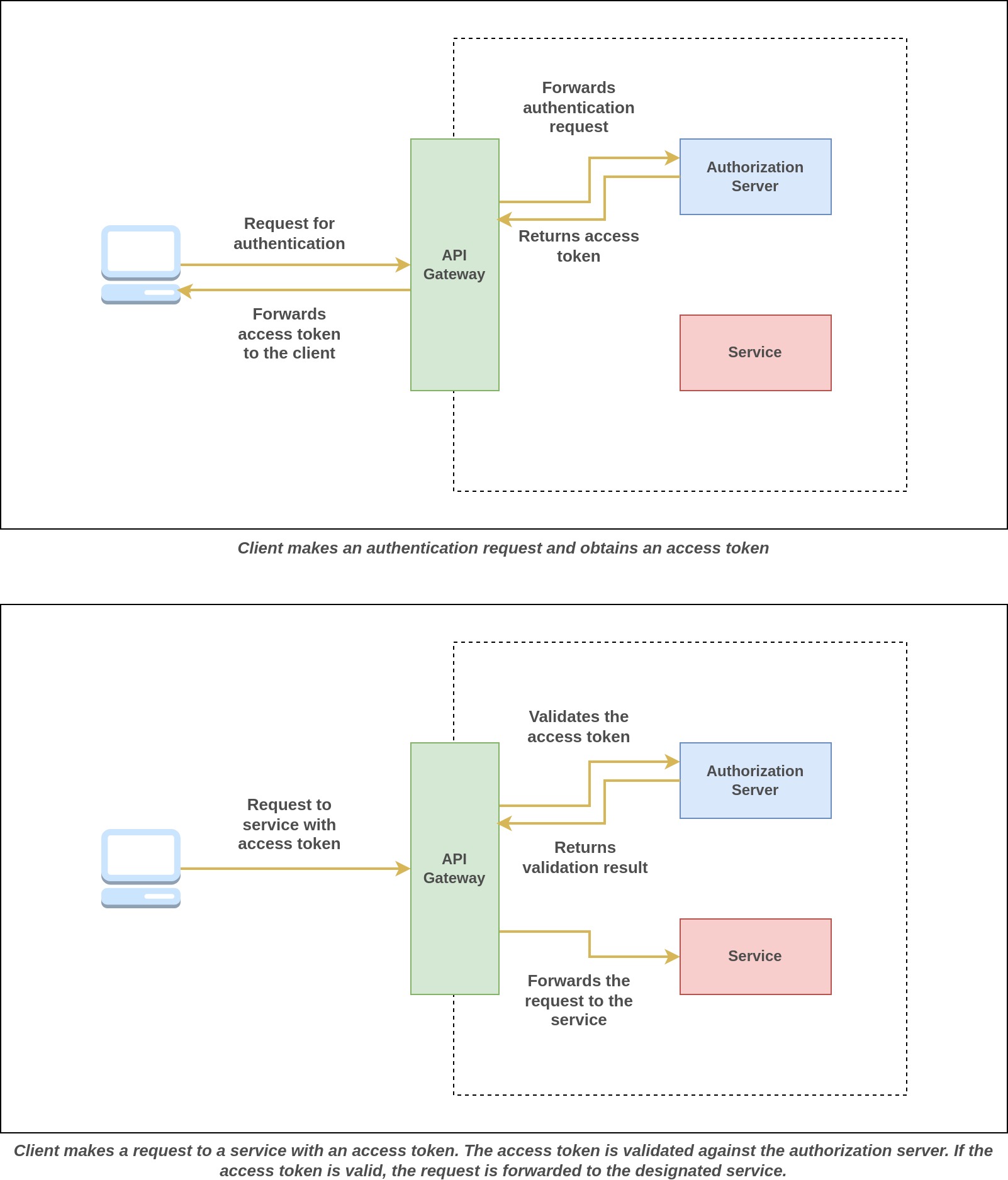
Login Flow
- A user initiates an authentication request with the API gateway, which then redirects the user to the login interface hosted by the authorization server.
- The user enters the credentials and logs in, granting consent to access requested resources if necessary.
- Upon successful login and granting consent, the client application is issued both an access token and an ID token.
Token Validation
- For all subsequent requests, these tokens are included with the request.
- The API Gateway extracts and verifies these tokens by checking them against the token introspection endpoint of the authorization server. Alternatively, the API Gateway can perform offline validation, using the authorization server's public key without making a direct call to the server. Offline validation reduces latency since it doesn't require a call to the authorization server.
- If the tokens are found to be valid, the request is directed to the relevant microservice. Otherwise, requests are rejected.
It's important to note that there are several steps involved when a user requests authentication from the authorization server and subsequently receives the tokens. To maintain clarity, we won't delve into these details in this section. However, we will briefly cover these steps in the section dedicated to OAuth 2.0 and OpenID Connect. For now, what's essential is that after a successful authentication with the authorization server, we obtain tokens as evidence of the successful authentication.
Authorization At Edge
Authorization can be handled at the API Gateway level, but to do so, the gateway would need to understand the functionalities of each microservice and the associated authorization conditions for each of them. Ideally, microservices should be self-contained to facilitate ease of modification and the rollout of new functionalities. Our goal is to simplify releases and enable independent deployment. If deploying a new microservice now entails both deploying the microservice itself and configuring authorization at the API gateway, it undermines the notion of independent deployment. Consequently, it's preferable to delegate the decision on whether a call should be authorized to the same microservice where the requested functionality resides. This approach not only makes the microservice more self-contained but also provides the flexibility to implement a zero-trust security model if desired.
Passing User Context
Upstream services often require user context when handling requests. This user context can be essential for making authorization decisions or simply for auditing user actions. At the API Gateway level, the user context can be included with each request heading to upstream services. If a service handling a request needs to make additional calls to other services to fulfill the request, it should also pass the user context along to these subsequent calls. There are two methods for transmitting user context within a request: adding it to headers or creating a JSON Web Token (JWT) containing the user data.
The first approach, involving headers, presents some security concerns, especially when the service-to-service communication lacks a secure channel. This vulnerability could expose the system to potential man-in-the-middle attacks. On the other hand, the second approach using JWT addresses this security issue by signing the data with a secret or private key. As a result, if the data is tampered with, upstream services can detect the manipulation and reject the request, enhancing overall security.
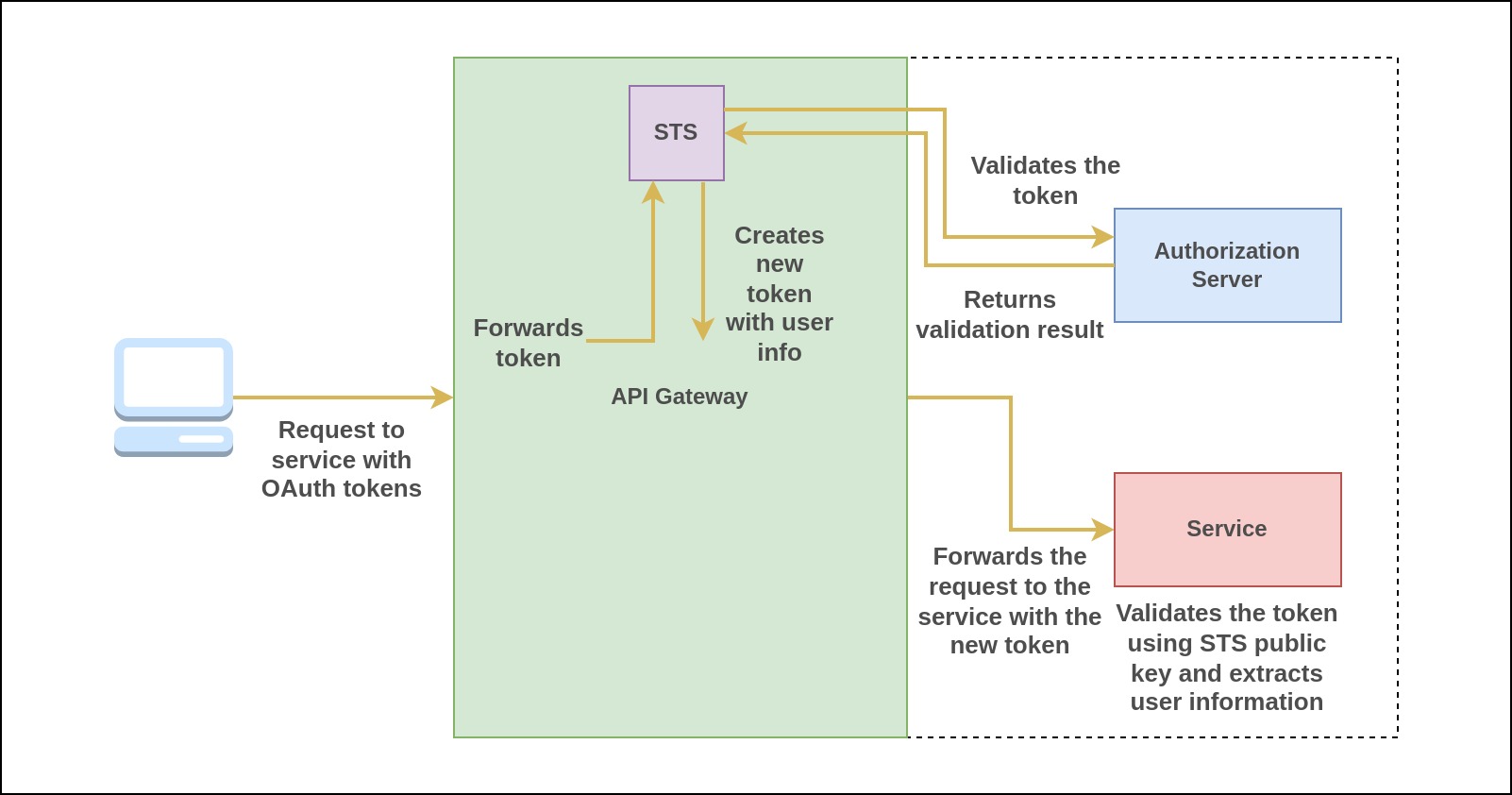
Here's how the API Gateway can create and pass user context using JWT:
- A Security Token Service, external or within the API Gateway is built to generate security tokens. It is mainly used to exchange OAuth 2.0 tokens for a new token containing the user information with a much shorter expiration period to securely communicate with upstream services.
- The API Gateway begins by extracting the OAuth 2.0 tokens from the request and forwards it to the STS.
- The STS validates the tokens and extracts the user information from the token. It then creates a new JWT token, with a shorter expiration time, incorporating this user data. This JWT is signed by the STS.
- The resulting JWT is added to the request's Authorization bearer token and the request is forwarded to the upstream service.
- When the upstream service receives the request, it retrieves the token and validates it using the public key of the STS.
- The upstream service extracts the user information from the token to enforce different authorization decisions.
Securing East/West Traffic
As the software industry increasingly embraces the Zero Trust security approach, the need to secure service-to-service communication has grown even more critical. In the Zero Trust mindset, trust is not taken for granted, even to services within our internal network boundaries. There's always a possibility that a malicious actor can breach the network, and once inside, the private network becomes as susceptible as the public internet. Therefore, the fundamental principle is to trust nothing and always verify. It's essential to implement security measures to thwart man-in-the-middle attacks, which aim to either intercept sensitive data or manipulate it for an unfair advantage.
Mutual Transport Layer Security (mTLS)
Malicious actors have the capability to impersonate either a client service or a service provider. Hence, it's imperative to authenticate both the client and the server. This is achieved through a protocol known as mutual Transport Layer Security (mTLS). Under this method, every service within the deployment must possess a private/public key pair. Both the client and server mutually authenticate each other by utilizing their respective certificates. Any attempt to create a container with the intent to impersonate a client or server will fail because it won't possess the necessary certificate to establish its validity as a genuine service.
Furthermore, with the utilization of mTLS, we can establish secure service-to-service communication. This ensures that data in transit remains both confidential and tamper-proof, as it's encrypted once both the client and server have been authenticated. Another advantage lies in the implementation of access control mechanisms between services, allowing us to specify which set of services are permitted to connect to a particular service.
JSON Web Tokens
Another approach to secure service-to-service communication is using JSON Web Tokens (JWTs), which operates at the application layer as opposed to mTLS. JWTs are capable of carrying a set of claims securely from one location to another in an immutable manner. These claims can encompass various information, such as user identity or permissions. To ensure their integrity, these claims are signed by the issuer of the JWT using its private key. Verification of the JWT can then be performed using the issuer's public key. Each microservice equipped with its private/public key pair can issue a JWT, and the recipient service can employ the issuer's public key to validate the identity of the service it's communicating with. Typically, JWTs are used in conjunction with TLS, where JWT provides authentication, while TLS ensures data integrity and confidentiality.
Passing a shared JWT between services
When the identity of the microservice itself isn't the primary concern, but rather the identity of the end user, JWT becomes a suitable choice over mTLS. In such cases, services don't need to authenticate each other. Instead, each request must carry the identity of the initiating end user, and if it doesn't, the receiving microservice rejects the request. However, as a best practice for enhanced security, even when service identity isn't the main focus, it's advisable to employ both mTLS for microservices and JWT for end-user identity protection. This dual approach creates an added layer of security, providing a robust defense mechanism.
Here's how the request flow works with this approach:
- An authenticated user initiates a request to the API gateway, providing their access token and ID token.
- The API Gateway validates these tokens and extracts their data, which is then encapsulated into a new JWT. This JWT is signed and given a much shorter expiration time, typically enough to complete the ongoing request to prevent any potential misuse.
- The JWT is included with the request as it moves to the required services.
- If additional calls to other services are required to fulfill the request, the same token is passed along to upstream services.
- Every service that receives the token must validate it using the public key of the token's issuer. If the token proves to be valid, the request is accepted; otherwise, it's rejected.
In this approach, JWT serves two crucial purposes. Firstly, it enables the secure transmission of end-user context across microservices in a tamper-proof manner. This is achieved because the JWT's claims set is signed by the issuer, preventing any microservice from altering its contents without rendering the signature invalid. Secondly, JWT enhances the security of service-to-service communications. A microservice can only access another microservice if it possesses a valid JWT issued by a trusted issuer. Consequently, any recipient microservice automatically rejects requests lacking a valid JWT.
Self-issued JWTs
In this approach, every service must possess its own unique public/private key pair. Each microservice is responsible for generating its JWT, signing it using its private key, and then transmitting it as an HTTP header (Authorization Bearer) along with the request to the target microservice, all conducted over a secure TLS connection. Given that the JWT in this scenario is a bearer token, the use of TLS is not just recommended but essential.
When the recipient microservice receives the request, it can identify the originating microservice by validating the JWT signature using the corresponding public key. Even if a self-issued JWT is employed, it's typically a requirement for communication between the two microservices to be conducted over TLS. This TLS layer ensures the confidentiality and integrity of the communication, offering a robust layer of security.
Service Level Authorization
Implementing authorization at the service level enables fine-grained authorization decisions based on domain-specific context. As we've explored, user context is relayed to upstream services, allowing for the integration of user context with domain-specific data to determine whether a particular user action should be permitted. In contrast to edge-level authorization, service-level authorization benefits from a more extensive contextual foundation, resulting in highly specific authorization decisions. If a user action is deemed unauthorized within this context, the request is promptly rejected and does not proceed to upstream services. It's crucial to conduct authorization checks at each service, as these decisions are now intricately tied to specific business domains, ensuring that access control aligns closely with the business logic and requirements.
For instance, when a user requests to view the details of an order, it's essential to prevent them from viewing someone else's order information. Instead, they should only be able to access their own order details. While at the API Gateway level, it might not possess the knowledge of whether the order belongs to the requesting user, the Order service has access to the relevant data required to make this decision. Consequently, implementing authorization at each service level enables finer-grained authorization decisions that are closely tied to the specific context and requirements of that service or business domain.
Furthermore, we have the capability to authorize the services themselves. This means we can specify a set of services that are allowed to establish connections with a particular service. Any service not included in this allowed list will be unable to connect to the designated service. This approach effectively reduces unnecessary access points within the service network. Importantly, it enhances security by complicating the task of an attacker who has compromised one service, as it becomes significantly more challenging for them to infiltrate other services at will. As a result, this approach acts as a deterrent, slowing down potential attackers and providing the security team with additional time for detecting and resolving security breaches.
Another method to implement distinct authorization policies is through the use of Open Policy Agent (OPA). OPA plays a pivotal role in microservice authorization by enabling the definition and enforcement of fine-grained access control policies without necessitating modifications to the microservice code. OPA is a lightweight and autonomous policy engine that operates independently of microservices. It empowers organizations to externalize access control policies and apply them at various points within a microservices deployment, including the API gateway. This approach ensures that access control policies can remain adaptable to evolving business requirements, all without the need for altering the code within the microservices themselves. The result is an augmentation of security and flexibility in managing access to microservices while preserving a clear separation of concerns.
Overview of OAuth 2.0 and OpenID Connect
OAuth 2.0 serves as an authorization framework specifically designed to address the challenge of access delegation. Its fundamental design allows users to grant limited access to their resources to third-party applications without sharing their credentials. This approach prevents third-party apps from gaining unrestricted access to all of a user's resources. It's worth noting that OAuth 2.0, in its essence, is not an authentication protocol, even though many people use it as such.
To address this limitation and introduce proper authentication capabilities, OpenID Connect was introduced. OpenID Connect serves as an extension of OAuth 2.0, enhancing it to support authentication. By adding an identity layer on top of OAuth 2.0, OpenID Connect enables client applications to not only ascertain which user has authenticated but also how and when the authentication occurred.
The Access Delegation Problem
When we want someone else to access a resource, like a microservice or an API, on our behalf to perform certain actions, we must grant them the appropriate access permissions. For instance, if we wish to allow a third-party application to read our Facebook status messages, we need to provide that application with the necessary permissions to access the Facebook API. Access delegation typically falls into two models:
- Access delegation through credential sharing.
- Access delegation without credential sharing.
Before the creation of OAuth 2.0, addressing the access delegation problem often led to highly problematic solutions. Consider Yelp's friends invite feature, which involved interactions with various email services. In this scenario, users were required to provide their actual email account credentials to Yelp. Yelp would then utilize these credentials to access the user's contacts. However, this method presented severe security concerns because, with the email credentials, Yelp gained unrestricted access to the entire email account, not just the contacts. This approach placed a heavy burden of trust on the user, as they had to place complete faith in the application to not engage in unauthorized activities with their credentials.
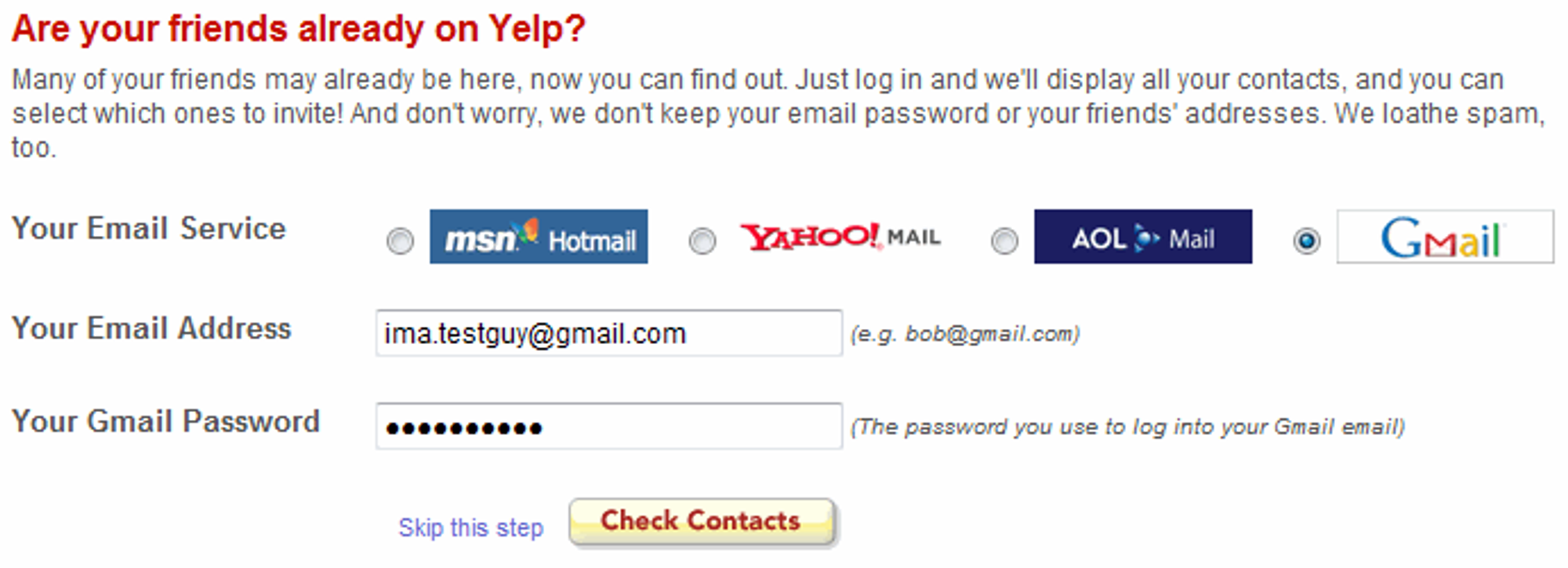
OAuth 2.0 resolves this issue by introducing a mechanism that avoids sharing any user credentials with third-party applications. Instead, an access token is provided to the application, granting it access to specific resources. However, it's important to note that this access token doesn't grant full access to the email account. Instead, it offers limited access, specifically to the user's contacts. Furthermore, the access token has a limited lifespan, unlike credentials that never expire. The application utilizes this access token to request the user's contacts from the email account server. Importantly, the application's capabilities are confined solely to viewing the user's email contacts, and even this limited access is only available for a restricted duration. This approach significantly enhances security and privacy compared to the previous method of sharing credentials.
OAuth 2.0 To The Rescue
As we've explored thus far, OAuth 2.0 effectively addresses the access delegation challenge. However, to understand how it accomplishes this, it's essential to become acquainted with certain key terminologies.
OAuth 2.0 Terminologies
- Resource Owner: This is the individual who has control over their owned resources and decides who should have access to them and at what level.
- Authorization Server: The authorization server is responsible for authenticating and identifying the resource owner. It grants access to third-party applications to access the resource owner's resources but only with the resource owner's consent.
- Resource Server: The resource server safeguards the resources owned by the resource owner. It allows access to these resources only when a valid token issued by the authorization server accompanies the access request.
- Client: The third-party web application, known as the client, acts on behalf of the resource owner and consumes the resource.
- Access Token: An access token is a credential issued by the authorization server to the client. It is used by the resource server to validate and grant access to protected resources. The resource server may communicate with the authorization server to validate the access token.
- Scope: Scopes offer a means to restrict the extent of access granted to an access token, ensuring that access is limited according to predefined permissions.
- Grant Type: Grant types, also known as flows, define the methods through which applications can obtain Access Tokens.
Various types of applications, each with distinct characteristics, can interact with our microservices. The method by which an application acquires an access token to access resources on behalf of a user hinges on these application attributes. When a client application seeks an access token from the authorization server, it selects a specific request/response flow, often referred to as a grant type within the OAuth 2.0 framework. This choice of grant type is influenced by the nature and requirements of the application, ensuring a suitable and secure access mechanism.
The OAuth 2.0 specification defines five primary grant types, each specifying a set of procedures for acquiring an access token. The outcome of executing a specific grant type is the attainment of an access token, which subsequently enables access to resources within our microservices. While the full exploration of all grant types exceeds the scope of this article, our focus here is solely on the grant type typically employed with microservice applications. Specifically, we will discuss the Authorization Code grant type.
Authorization Code Grant Type
The authorization code grant is commonly used in desktop applications, web applications (those accessed through web browsers), and native mobile applications capable of managing HTTP redirects. In this flow, the client application starts by sending a request to the authorization server, asking for an authorization code. This request includes the application's client ID and a URL where the user will be redirected after a successful authentication process.
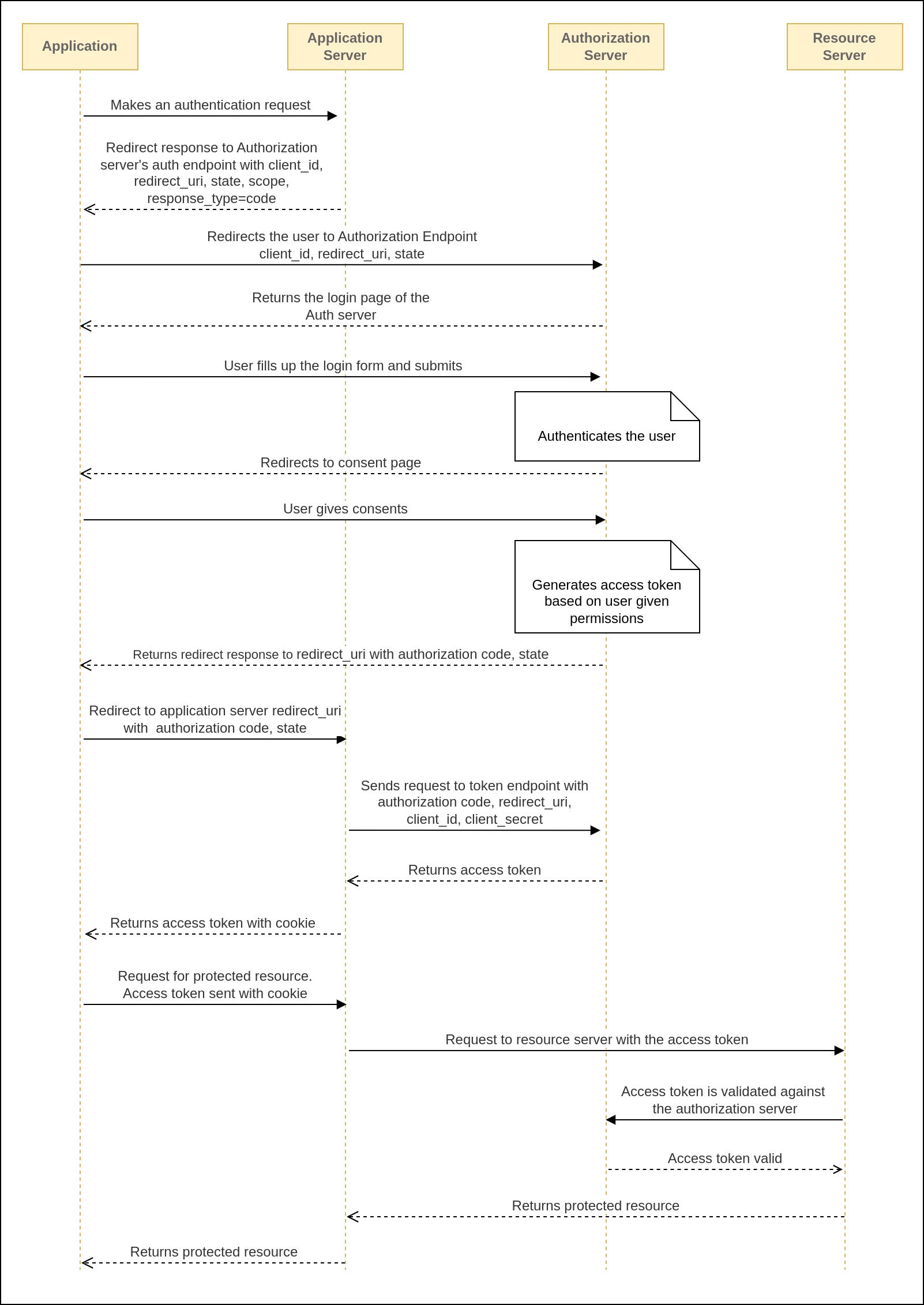
The client application begins by making an authorization code request. In this request, it includes important parameters like the client ID (often equivalent to the application ID), the redirect URI (where the user will be sent after authentication), and the response type. The response type tells the authorization server that it should respond with an authorization code. This code is sent back as a query parameter in an HTTP redirect to the specified redirect URI. Essentially, the redirect URI is where the authorization server directs the user's web browser once the authentication process is successfully completed. One optional parameter that can be included in the authorization request is scope. When making the authorization request, the application can request the scopes it requires on the token to be issued.
Upon receiving the authorization request, the authorization server conducts initial checks on the client ID and redirect URI. Assuming these parameters are valid, it then displays the authorization server's login page to the user (assuming there's no active user session on the authorization server). On this login page, the user is required to enter the username and password. It's important to emphasize that we're submitting our login credentials on the authorization server's page, not the resource server's. The resource server remains unaware of this login process taking place on the authorization server. Once the username and password are successfully verified, the authorization server generates an authorization code and sends it to the user's web browser through an HTTP redirect. This authorization code is included as part of the redirect URI.
https://www.example.com/login?code=ghe456ma-4qfb5-2jriqcv
The authorization code is delivered to the user's browser through the redirect URI, and this transfer must occur securely over HTTPS to protect it from interception. However, since this code is part of a browser redirect, it's visible to the end user and may also be recorded in server logs. To minimize the risk of this data being compromised, the authorization code typically has a brief lifespan, often no longer than 30 seconds, and it can only be used once. If someone attempts to use the code more than once, the authorization server invalidates all tokens that were previously issued based on that code to enhance security.
Once the authorization code is obtained, the client application initiates a request to the authorization server, asking for an access token in exchange for the authorization code. The authorization code grant type, necessitates the inclusion of the client ID and client secret as part of this code exchange process. Additionally, it mandates the inclusion of the grant_type parameter, set to "authorization_code", along with the code itself and the redirect URI, all conveyed within the HTTP request to the authorization server's token endpoint. After verifying these details, the authorization server responds by issuing an access token to the client application in an HTTP response.
{
"access_token": "a821de09bec4-863a-40c8-104dddb30204",
"refresh_token": "asdgahr7j3ty3-vadt5-heasdcu8-as3t-hdf67",
"token_type": "bearer",
"expires_in": 3599
}
In the authorization code grant process, which involves the user, client application, and authorization server, the user's credentials are not directly shared with the client application. Instead, the user enters their credentials exclusively on the authorization server's login page. This approach ensures that the client application never gains access to the user's login information, enhancing security. As a result, this grant type is well-suited for scenarios where we need to provide fine-grained access to resources we own in a server to web, mobile, and desktop applications that we may not completely trust.
Validating The Token
Once the client application obtains the access token, it can include it in the authorization header as bearer token in the requests it sends to the resource server. The resource server then extracts and validates the access token. The method of validation depends on the type of access token issued by the specific authorization server.
Firstly, the resource server can validate the token by making a request to the authorization server's token introspection endpoint. Secondly, if the token is self-contained, like a JWT (JSON Web Token), it can validate itself using the authorization server's public key. However, if the token is a reference token, the only option is to validate it through the authorization server's token introspection endpoint. It's worth noting that self-validation is more efficient in terms of performance since it doesn't require additional network calls.
One challenge with self-validating tokens is that if a token is revoked prematurely, the resource server won't be aware of it because revocation is handled by the authorization server. To address this issue, there are a couple of solutions.
One approach is to issue short-lived access tokens and use the refresh token flow to obtain new access tokens after they expire. This limits the time during which an access token can be considered valid after revocation by the authorization server.
Another solution is for resource servers to subscribe to the authorization server for revocation events. When a token is revoked, the authorization server sends a message through a message broker to the resource server. The resource server can then maintain a list of revoked tokens until their expiration and check this list when validating tokens. This way, the resource server can detect and reject revoked tokens.
Once the access token has been successfully validated, the resource server proceeds to process the incoming request. However, it's essential to note that if the access token contains specific permissions or scope information, the resource server must use this scope to make appropriate authorization decisions regarding what the requester is allowed to do.
OpenID Connect
OAuth 2.0 was originally designed for authorization, but many people started using it for authentication, which it wasn't specifically created for. To address this, OpenID Connect was developed as an extension of OAuth 2.0. OpenID Connect serves as an identity layer that extends OAuth 2.0's capabilities. It introduces a concept called the "ID token," which is essentially a JSON Web Token (JWT) containing authenticated user information, such as user claims and relevant details. When an authorization server generates an ID token, it signs the JWT's contents using its private key. To ensure the ID token is valid, any application receiving it must verify the signature of the JWT. This helps establish the authenticity of the user's identity during authentication processes.
An ID token is used by an application to retrieve information like a user's username, email address, and phone number. On the other hand, an access token is a credential that an application uses to access a protected API, either on behalf of a user or by itself. OAuth 2.0 offers only an access token, while OpenID Connect offers both an access token and an ID token, providing more comprehensive user identity information for applications to utilize.
An ID token is typically acquired when requesting an access token. To receive an ID token in the response, we must include "openid" as a scope when making the token request. This informs the authorization server that we want an ID token along with the access token.
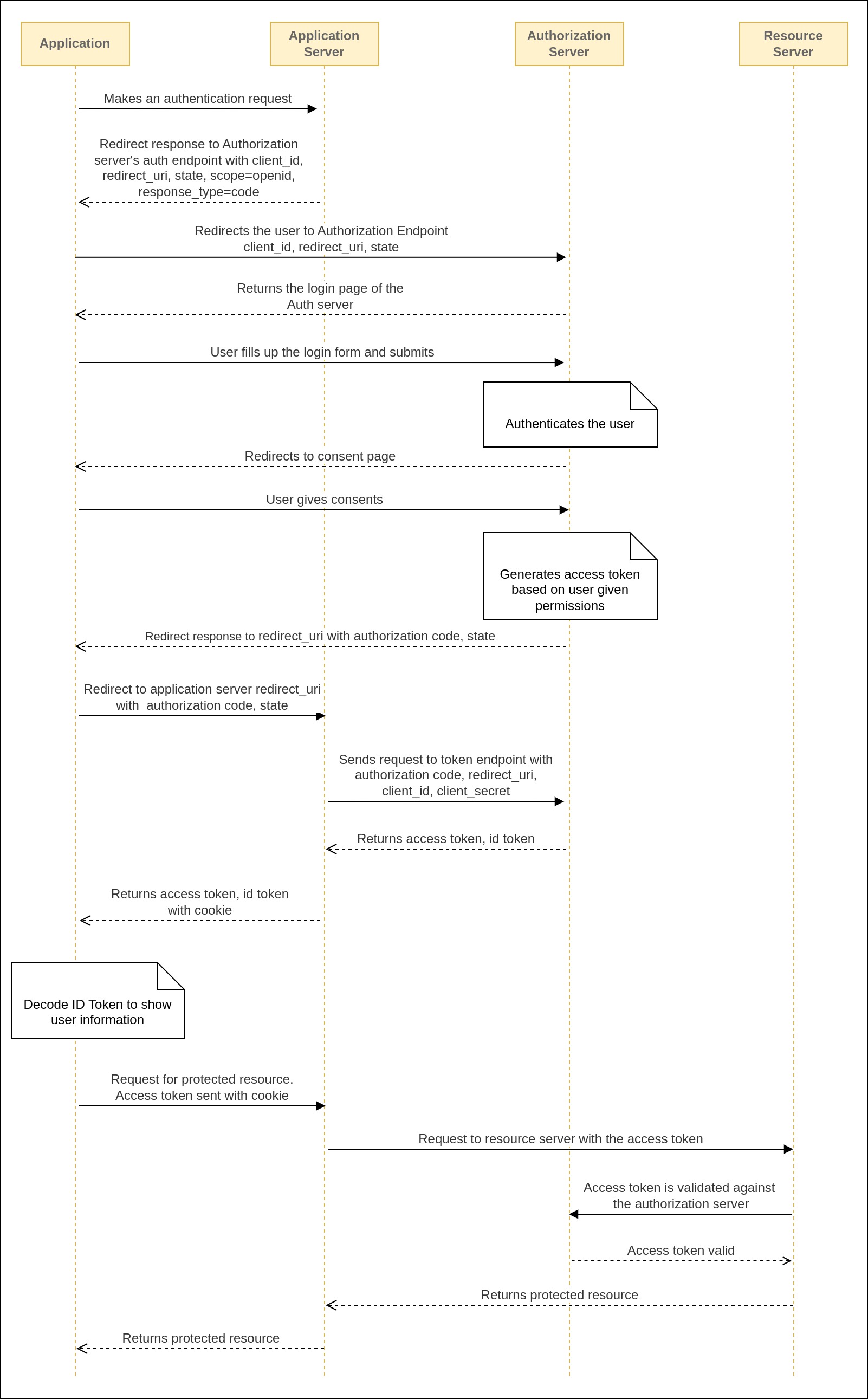
The process for OpenID Connect closely resembles OAuth 2.0, with one notable difference during the authorization code exchange step. In this step, we not only receive an access token but also an ID token as part of the response, as depicted in the image above.
Overview of Mutual Transport Layer Security (mTLS)
Most of us probably have already heard of TLS, the technology that ensures secure communication between a client and a server, safeguarding data confidentiality and integrity. We often encounter TLS in action when browsing websites that use the HTTPS protocol. Without TLS, data can be intercepted or tampered with by a malicious party positioned between the client and server. When we visit a site like Amazon, we notice the connection is secured with a certificate. Now, think of mTLS as an extension of TLS that adds an extra layer: not only does it let the client verify the server, but it also allows the server to verify the client. Hence, it's called Mutual TLS (mTLS). If either the client or server fails to present a valid certificate during the initial handshake, the connection won't be established. This is significantly more secure than TLS because it mandates client authentication using a valid certificate, which is challenging for a malicious client to obtain.
Benefits Over TLS
Mutual TLS (mTLS) offers similar advantages to regular TLS. It allows the client to verify the server's identity and ensures that data in transit remains encrypted, preventing unauthorized access or modifications. However, mTLS goes a step further by enabling the server to verify the clients. This client verification is crucial because malicious actors can attempt to send harmful requests to the server.
In a microservices environment, a malicious actor might create a container to mimic a legitimate client service and send harmful requests to a receiving service. By using mTLS, the receiving service can confirm the sender's authenticity. This means that even if a bad actor gains access to the network, they won't be able to send malicious requests to other services.
Moreover, mTLS allows for more fine-grained access control configurations between services. We can specify that only a particular set of services is allowed to access a specific receiving service. Services not on this approved list won't be able to send requests to the designated receiving service. Even if credentials are somehow compromised, an impersonating client service would still require a valid certificate, making unauthorized access highly unlikely.
How It Works In Microservice Environment
Certificate Authority (CA)
In a microservices system, the various services need to communicate with each other, typically through a private network that's isolated from the public internet. To ensure the security of this communication using mutual TLS (mTLS), a trusted Certificate Authority (CA) is required. This CA is a self-managed entity that all services within the microservices architecture trust.
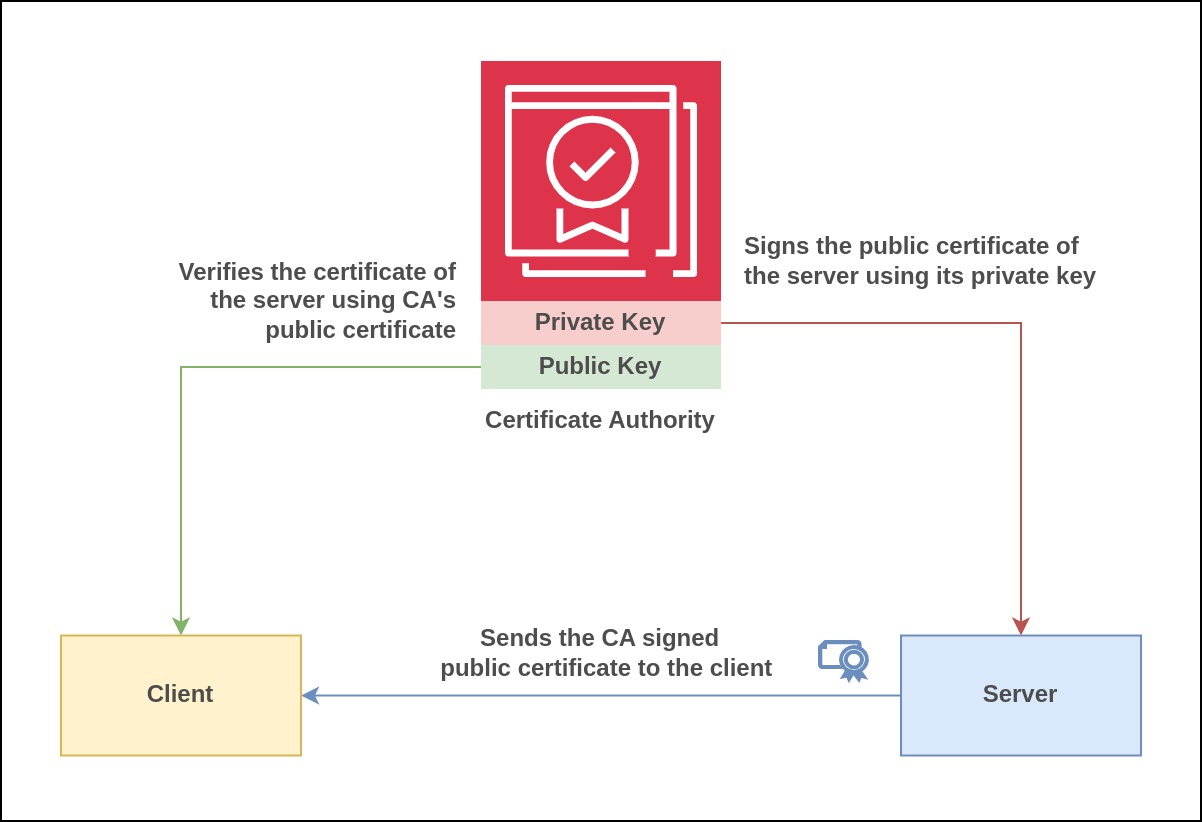
The CA issues certificates to each individual service in the microservices network. The Certificate Authority (CA) is responsible for putting its digital signature on the certificate of a service, which includes the service's public key, using the CA's own private key.
When one service needs to verify another service's certificate, it does so by checking if the certificate has been signed by the trusted CA. This validation involves using the CA's public key. If the certificate passes this verification, it means that it was indeed signed by the CA and can be considered trustworthy. Through the information contained in the certificate, such as the service's identity, the receiving service knows which client service is attempting to establish connection.
The Handshake
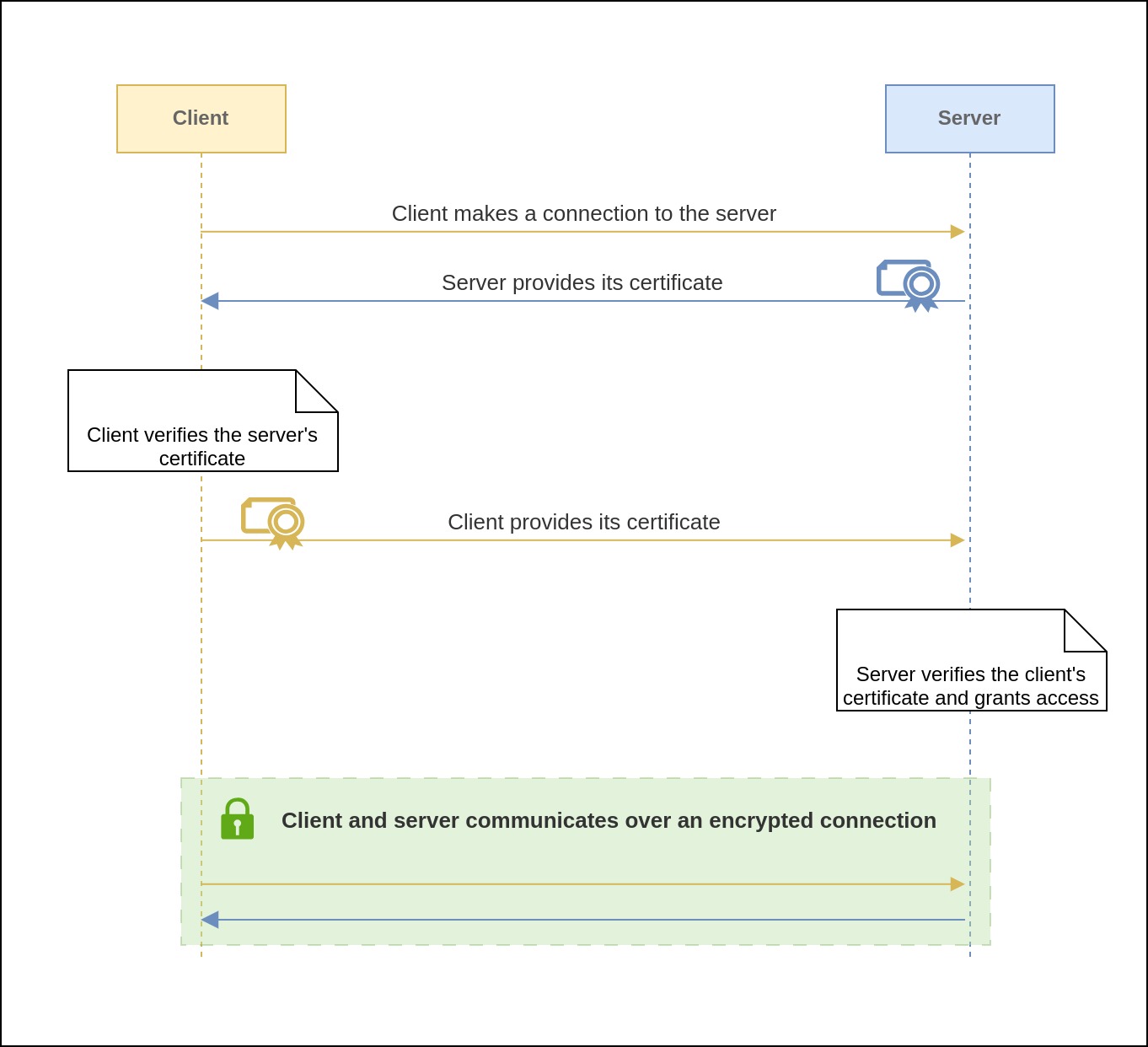
Before two parties can establish a connection, they engage in a handshake process to confirm the validity of their certificates. This handshake process unfolds as follows:
- The client service initiates a request to the receiving service.
- The receiving service presents its TLS certificate to the client service.
- The client service verifies the certificate.
- The client service presents its certificate.
- The receiving service verifies the certificate.
- The receiving service grants access.
- Both parties can now securely exchange information over an encrypted TLS connection.
Why mTLS Is Not Used In Public Network
In the public internet, there are far more clients than servers, possibly numbering in the billions. Managing and verifying certificates for such a vast number of clients through central Certificate Authorities is an incredibly challenging task. However, Mutual TLS shines in private networks where a limited number of servers communicate within an organization network that operates on a Zero Trust model. In this scenario, every client and server is authenticated using certificates, and nothing is inherently trusted within the organization's network. This level of security isn't feasible for the public internet, which is why a different authentication method is needed.
Clients use certificates from trusted Certification Authorities to verify servers, preventing spoofing attacks, data eavesdropping, and data tampering. However, servers typically do not verify clients using certificates. Instead, they often have their own authentication methods, such as using usernames and passwords. Additionally, requiring end-users to handle and install client certificates can be cumbersome and less user-friendly when compared to traditional authentication methods like usernames and passwords. For these reasons, the usage of TLS is widespread in the public internet.
Service Mesh Makes It Easier
As the number of microservices in an application increases, developers may choose to incorporate a specialized infrastructure layer known as a service mesh to manage service-to-service communication. A service mesh includes a proxy sidecar component alongside each microservice and commonly employs mutual Transport Layer Security (mTLS) for secure communication between these proxy components.
Microservice security play a pivotal role in safeguarding modern software architectures. As organizations continue to embrace microservices for their scalability and agility, it is essential to prioritize security at every step from the very beginning. By implementing patterns like authentication and authorization, mTLS, JWTs, and API gateways and embracing modern security mindsets like Zero Trust, we can fortify our microservices against potential threats. Remember, security is an ongoing process, and staying vigilant and implementing security at every level of the system is crucial to protect our microservices and the sensitive data they handle. So, invest in robust security patterns and practices to ensure that our microservices remain resilient in the face of today's digital challenges.
Explore More
Topics
Are you new? Start here
Microservice Architecture
Patterns & best practices to achieve scalability, flexibility, and resiliency.
Event Driven Architecture
Embrace Scalable, Responsive, and Resilient Systems through Event-Driven Paradigm.
System Design
Explore modern software solutions to scale to the horizon.