In today's fast-paced digital landscape, the role of computers has evolved beyond a single device, becoming inherently distributed to handle the increasing load of a world moving towards quick digitization. Consequently, software solutions now span multiple devices and regions, necessitating real-time data synchronization and replication for maintaining data consistency and seamless operations across various machines and systems. The importance of moving data swiftly is driven by factors such as interoperability, flexibility, disaster recovery, analytics and many more. Enter Change Data Capture (CDC), a powerful technology facilitating efficient capture of the changes in data and propagation from a source system to one or more target systems, enabling near real-time data movement between diverse systems. In this article, we will delve into the process of replicating a PostgreSQL database using CDC with Kafka, a widely adopted distributed streaming platform.
Change Data Capture
Change Data Capture is a technique that captures the changes made to a database and transforms them into a stream of events. These events represent individual inserts, updates, and deletes made to records in the database. Unlike traditional replication methods, which replicate entire datasets, CDC captures only the changes, resulting in reduced network overhead and improved data replication efficiency.
There are multiple common Change Data Capture methods that you can implement depending on your application requirements and tolerance for performance overhead. Here are the common methods, how they work, and their advantages as well as shortcomings.
Log Based
Databases are equipped with transaction logs, often referred to as redo logs, which play a vital role in ensuring data integrity and recovery in case of system crashes. These logs store a chronological record of all database events, allowing the database to be restored to a consistent state after a failure. One powerful approach to capture data changes is log-based Change Data Capture (CDC), where new database transactions, encompassing inserts, updates, and deletes, are directly read from the source database's native transaction logs.
By leveraging the information stored in these logs, log-based CDC provides a non-intrusive and efficient method to track data modifications in real-time. As soon as a change is committed to the database, it is recorded in the transaction log, and CDC mechanisms can extract and transform this information into a stream of events. These events can then be propagated to other systems, data warehouses, or analytical platforms, ensuring data synchronization and consistency across the entire ecosystem.
The advantages of log-based CDC include minimal impact on the source database's performance, as the extraction process operates separately from the main transactions. Additionally, the captured changes are delivered in the order they occurred, preserving data integrity and maintaining the sequence of operations across systems.
Trigger Based
Application-level change data capture (CDC) using database triggers and shadow tables is a common method favored by some users due to its native support in certain databases and the ability to maintain an immutable, detailed log of all transactions. Triggers, which fire before or after INSERT, UPDATE, or DELETE commands, are employed to create a change log in shadow tables. However, this approach comes with significant disadvantages, primarily the requirement of triggers for each table in the source database and the resulting overhead on the database's performance. With triggers processing multiple writes for every data change, the application experiences reduced efficiency and an increased management burden when maintaining these triggers as the application evolves.
Modification Timestamp Based
A table can incorporate a last modification timestamp column, which updates every time a specific row changes. If this column exists and is consistently updated whenever a row changes, we can implement change data capture based on the modification timestamp. This technique is an application-level approach, requiring diligent monitoring to ensure all updates result in a change to the last modification date, ensuring data consistency. While this method does not demand external tooling, it necessitates querying the database at regular intervals to identify rows that changed since the last extraction. As a result, it places additional strain on the database, as data extraction occurs through periodic queries. One limitation of this approach is that it does not capture deletions automatically. To handle deletions, supplementary scripts are needed to be implemented.
Kafka: A Streaming Platform
Kafka is an open-source, distributed streaming platform that excels at handling real-time data streams. It is built to handle high-throughput and low-latency data streams, making it an ideal solution for Change Data Capture. Kafka maintains a durable, fault-tolerant log of records, where each record is a combination of a key, a value, and a timestamp. These records are organized into topics, and consumers can subscribe to specific topics to process the data streams.
Capturing CDC Events
Setting Up The Infrastructure
The overall architecture of the CDC system consists of five main components: the Source Database, Debezium, Kafka Cluster, Consumer, and Target Database. The Source Database is the origin of data and undergoes changes over time. Debezium acts as the CDC engine, capturing these changes by monitoring the database's transaction logs or write-ahead logs. It transforms the changes into CDC events, which are then written to specific Kafka topics by the Debezium connector. The Kafka Cluster, a distributed infrastructure, stores and distributes these events across multiple brokers and partitions. Consumers subscribe to the Kafka topics to read the CDC events and process them in real-time. The Target Database represents the destination system where the CDC events are ultimately utilized, such as for replication, synchronization, or analytics. This architecture enables seamless, real-time data integration, and its decoupled nature ensures scalability, reliability, and fault-tolerance in complex data ecosystems.
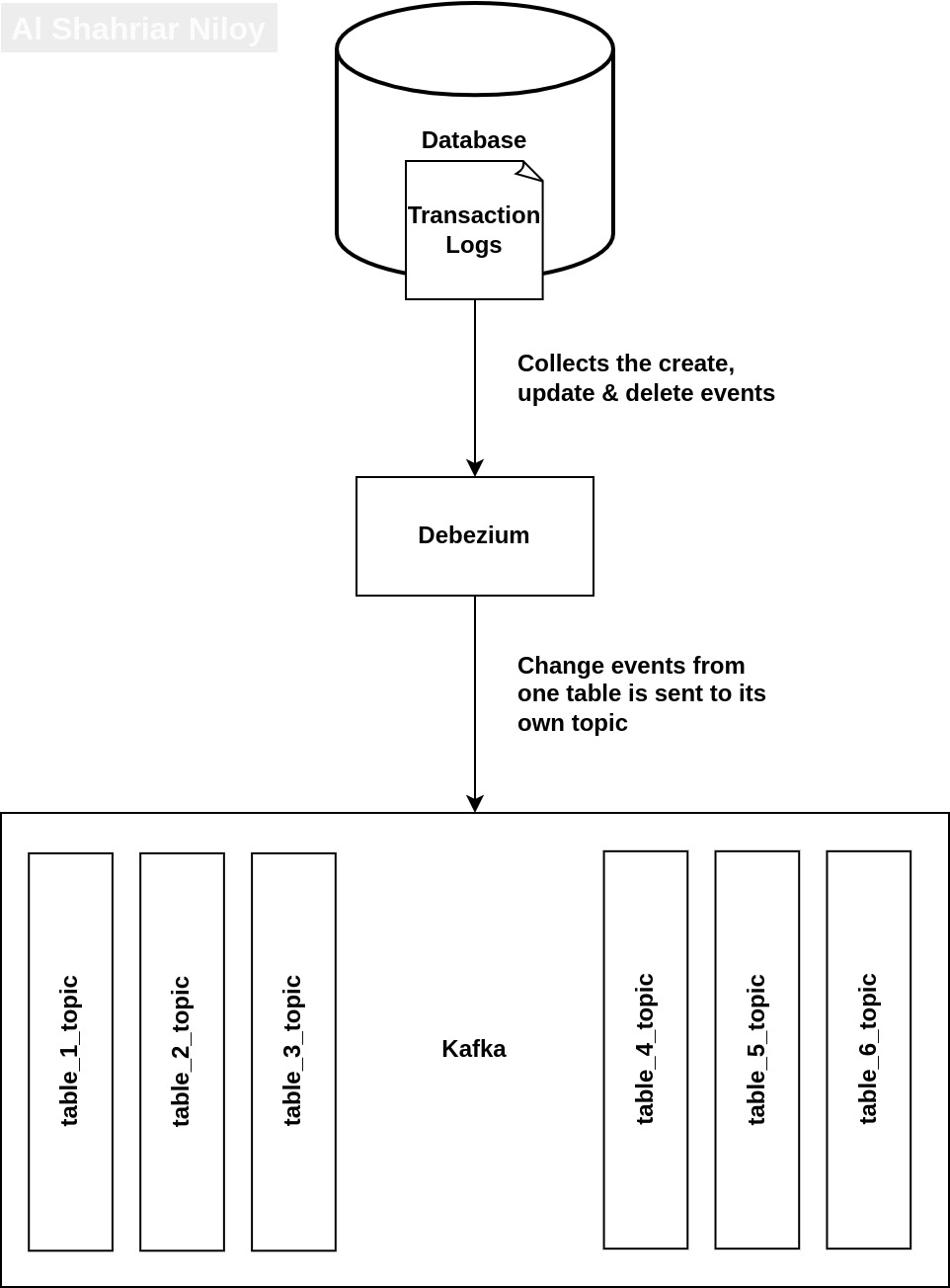
Let's delve into the main topic and capture some CDC events. To achieve this, we need to set up the infrastructure first. Fortunately, we can accomplish this easily using Docker Compose. Begin by creating a dedicated folder for the project, and within it, create a file named "docker-compose.yml." Now, paste the provided code into this file and save it.
version: '3.9'
services:
postgres:
image: postgres:14.8
ports:
- "5355:5432"
environment:
- POSTGRES_PASSWORD=root
volumes:
- ./postgres:/var/lib/postgresql/data
zookeeper:
image: confluentinc/cp-zookeeper:6.0.14
ports:
- "2181:2181"
- "2888:2888"
- "3888:3888"
environment:
- ZOOKEEPER_CLIENT_PORT=2181
kafka:
image: confluentinc/cp-kafka:6.0.14
ports:
- "9092:9092"
- "29092:29092"
depends_on:
- zookeeper
environment:
- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=LISTENER_EXT://localhost:29092,LISTENER_INT://kafka:9092
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=LISTENER_INT:PLAINTEXT,LISTENER_EXT:PLAINTEXT
- KAFKA_LISTENERS=LISTENER_INT://0.0.0.0:9092,LISTENER_EXT://0.0.0.0:29092
- KAFKA_INTER_BROKER_LISTENER_NAME=LISTENER_INT
- KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR=1
connect:
image: debezium/connect:2.4
ports:
- "8083:8083"
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=1
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
depends_on:
- zookeeper
- kafka
Lastly, execute the given command to set up the infrastructure.
docker compose up —build -dTake note that we have established a bind mount for PostgreSQL, enabling easy modifications to its configuration file. We'll delve into the specifics later on.
Setting Up PostgreSQL
To configure PostgreSQL for capturing CDC events using Debezium, follow these steps:
- Open the project root folder and locate the "postgres" folder.
- Use the file explorer to open the "postgresql.conf" file.
- Add the following line at the bottom of the file:
- Save the changes in the "postgresql.conf" file.
- Restart the PostgreSQL container for the configuration to take effect.
- Now, create a database named "source" and inside it create a table named "customer" using the provided SQL statement:
- Create two client databases named "clientdb1" and "clientdb2," and similarly create the "customer" table in each of these databases using the same SQL statement as above.
- Finally, create or make a note of a database user that you want the Debezium connector to use for capturing CDC events from PostgreSQL.
wal_level=logicalCREATE TABLE IF NOT EXISTS public.customer
(
firstname character varying COLLATE pg_catalog."default",
lastname character varying COLLATE pg_catalog."default",
id integer NOT NULL,
CONSTRAINT customer_pkey PRIMARY KEY (id)
);Setting Up Debezium
- Create a file “debezium.json” with the following content on the project root folder.
- In this file, we must ensure that the "database.user" property is set to a user with the necessary login and replication permissions. We should set this property to the user that was created or noted down during the PostgreSQL setup. Alternatively, we can use the default user "postgres" since it already possesses both of these required permissions.
- Make a POST request to Debezium Connection to add the configuration. The response will be a JSON of the configuration sent to Debezium.
{
"name": "debezium-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"plugin.name": "pgoutput",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "root",
"database.dbname": "source",
"database.server.name": "myserver",
"topic.prefix": "myserver",
"table.include.list": "public.customer"
}
}curl -i -X POST \
-H "Accept:application/json" \
-H "Content-Type:application/json" \
127.0.0.1:8083/connectors/ \
--data "@debezium.json"
Upon successful completion of these steps, Debezium will automatically capture CDC events from PostgreSQL and
seamlessly forward them to specific topics on Kafka. Since CDC events are inherently table-specific, they will be
delivered to corresponding table-specific topics. These topics will be named following the pattern given below.
<topic.prefix>.<schema>.<tablename>
Consuming CDC Events From Kafka Topics
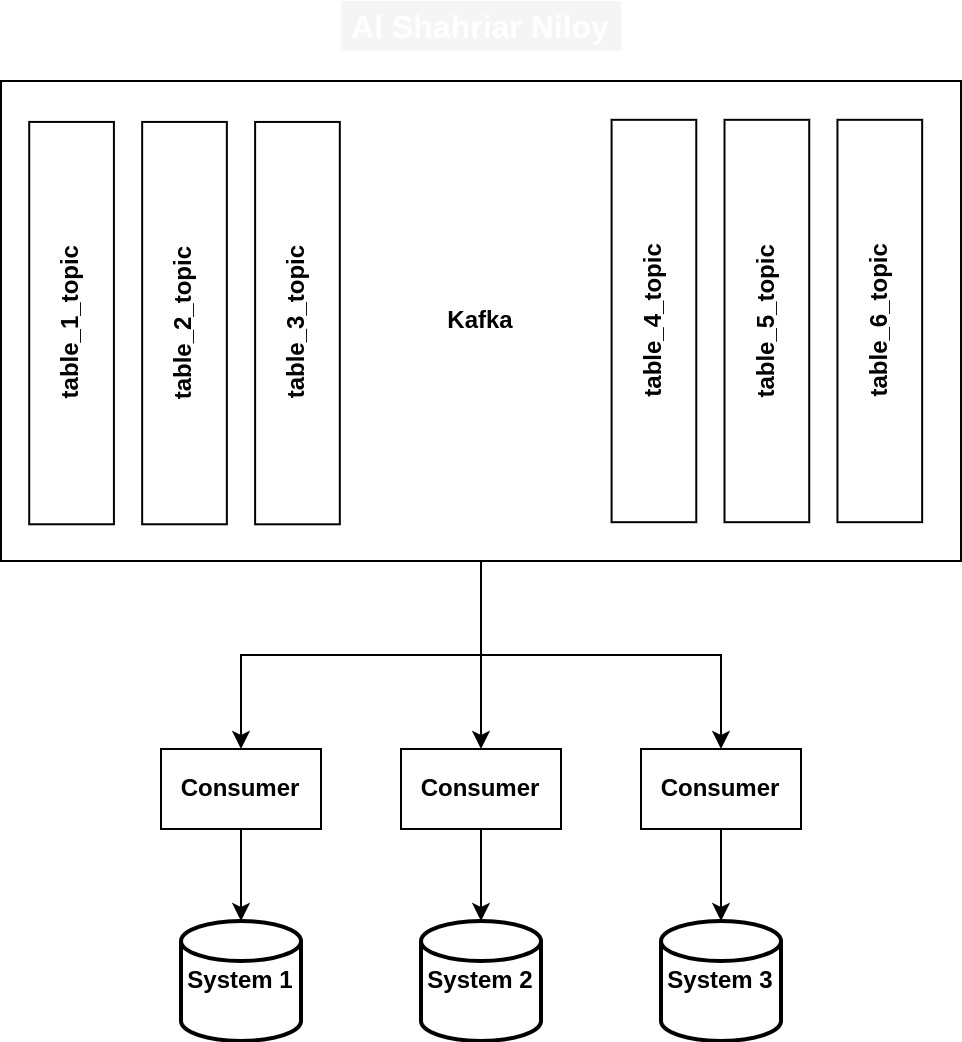
Now that we have the events in Kafka, we can start consuming the events and propagate the changes to different systems. For this, we are going to use a simple node application. Create the following three files in the root directory of the project.
{
"name": "pgcdc",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"start": "node index"
},
"keywords": [],
"author": "",
"license": "ISC",
"dependencies": {
"kafkajs": "^2.2.4",
"pg": "^8.11.0",
"pg-hstore": "^2.3.4",
"sequelize": "^6.32.1"
}
}const { Kafka } = require("kafkajs");
const Sequelize = require("sequelize");
const CustomerModel = require("./customer.model");
const clientdb1 = new Sequelize(
"postgres://postgres:root@localhost:5355/clientdb1"
);
const clientdb2 = new Sequelize(
"postgres://postgres:root@localhost:5355/clientdb2"
);
const DB_OPERATIONS = {
CREATE: "c",
UPDATE: "u",
DELETE: "d",
};
const clients = [
{
name: "SpaceX",
consumerGroupName: "spacex",
sequelize: clientdb1,
},
{
name: "Blue Origin",
consumerGroupName: "blue-origin",
sequelize: clientdb2,
},
];
const tables = [
{
name: "customer",
modelName: "Customer",
schema: "public",
topicName: "myserver.public.customer",
duplicateColumnNames: ["id"]
},
];
function initializeModels() {
CustomerModel(clientdb1);
CustomerModel(clientdb2);
}
async function handleCDCEvent(event, client) {
if (!event) return;
const { source: { table: tableName } } = event;
const table = tables.find((t) => t.name === tableName);
const { duplicateColumnNames } = table;
const model = client.sequelize.models[table.modelName];
if (
event.op === DB_OPERATIONS.CREATE ||
event.op === DB_OPERATIONS.UPDATE
) {
try {
await model.bulkCreate(
[event.after],
{
updateOnDuplicate: Object.keys(model.rawAttributes),
conflictAttributes: duplicateColumnNames
}
);
} catch (err) {
console.error(err);
throw new Error('An error occurred while creating or updating a record.');
}
} else if (event.op === DB_OPERATIONS.DELETE) {
try {
const where = {};
duplicateColumnNames.forEach(dcn => where[dcn] = event.before[dcn]);
await model.destroy({ where });
} catch(err) {
console.error(err);
throw new Error('An error occurred while deleting a record.');
}
}
}
async function initializeKafka() {
try {
const kafka = new Kafka({
clientId: "pgcdc",
brokers: ["localhost:29092"],
});
for (const client of clients) {
const consumer = kafka.consumer({
groupId: client.consumerGroupName,
});
await consumer.connect();
for (const table of tables) await consumer.subscribe({ topic: table.topicName });
await consumer.run({
autoCommit: false,
eachMessage: async ({ topic, partition, message }) => {
console.log({
value: message.value && message.value.toJSON(),
topic,
partition,
});
if (message.value) {
await handleCDCEvent(JSON.parse(Buffer.from(message.value.toJSON().data).toString()).payload, client);
}
await consumer.commitOffsets([
{
topic,
partition,
offset: (Number(message.offset) + 1).toString(),
},
]);
},
});
}
} catch (err) {
console.log(err);
}
}
initializeModels();
initializeKafka();const { DataTypes } = require("sequelize");
module.exports = function(sequelize) {
return sequelize.define(
"Customer",
{
id: {
type: DataTypes.INTEGER,
allowNull: false,
primaryKey: true
},
firstname: {
type: DataTypes.STRING
},
lastname: {
type: DataTypes.STRING
},
},
{
tableName: "customer",
timestamps: false
}
);
};Run the following commands to start the consumer
npm install
npm start
Once the application is up and running, the client consumers subscribe to the topic associated with the "customer" table. Whenever an event surfaces in the topic, the consumer handles it by replicating the changes to the corresponding client databases. To ensure reliable data propagation, we run Kafka in at least once mode with idempotent consumers. This approach guarantees that all changes are successfully propagated to the client databases without duplication.
With upsert, even if an insert event is processed multiple times, the consumer intelligently handles the data, creating a new record only if it doesn't already exist and updating it if it does. This approach effectively prevents the creation of redundant data in the client databases, maintaining data integrity and consistency throughout the process.
Assuming all configurations and setups are successful, we can now witness the changes made to the "customer" table in the source database being efficiently replicated to the client databases. To ensure the effectiveness of the replication process, try performing various actions such as inserts, updates, and deletes on the "customer" table.
Replicating a PostgreSQL database using Change Data Capture with Kafka is a powerful approach to achieve real-time data synchronization and ensure data consistency across systems. Kafka's high throughput, fault tolerance, and scalability, combined with CDC's efficient data capture, make it an excellent choice for modern data replication scenarios. By implementing CDC with Kafka, organizations can build robust, real-time data pipelines and enable data-driven decision-making at scale.
Explore More
Topics
Are you new? Start here
Microservice Architecture
Patterns & best practices to achieve scalability, flexibility, and resiliency.
Event Driven Architecture
Embrace Scalable, Responsive, and Resilient Systems through Event-Driven Paradigm.
System Design
Explore modern software solutions to scale to the horizon.