In a world where time is the new currency, the concept of a cache has become a crucial component in enhancing the speed and efficiency of data retrieval. Cache acts as a swift, temporary storage layer that holds a subset of data, reducing latency and making your digital experience smoother than ever before. It is strategically positioned between the application and a data source which is usually much slower. The rationale behind this setup is simple: fetching a small amount of frequently accessed data from a fast storage is significantly better than retrieving it from a storage with slow access. Hence, their presence is ubiquitous, spanning across realms ranging from computer hardware and Content Delivery Networks (CDNs) to Domain Name Systems (DNS) and database caches (and many more), underscoring their indispensable role in the tech industry.
Distributed Caching
In a distributed caching setup, information is held in memory across numerous servers or nodes, creating a cluster of distributed cache. This permits applications to rapidly retrieve frequently accessed data without the need to repeatedly obtain it from slower and more resource-demanding origins such as databases or external services. With a cluster of cache servers in place, the application gains the ability to manage higher loads, thanks to the availability of multiple cache servers to distribute the workload. This prevents the cache servers from becoming overwhelmed by the demand. This infrastructure flexibility also permits the seamless integration of additional cache servers to accommodate further increases in demand. In contrast to depending on a single cache server, which would entail the risk of a single point of failure, a distributed caching system sidesteps this predicament. Even in cases where one or more cache servers experience downtime, the presence of numerous other servers ensures the continuous operation of the application.
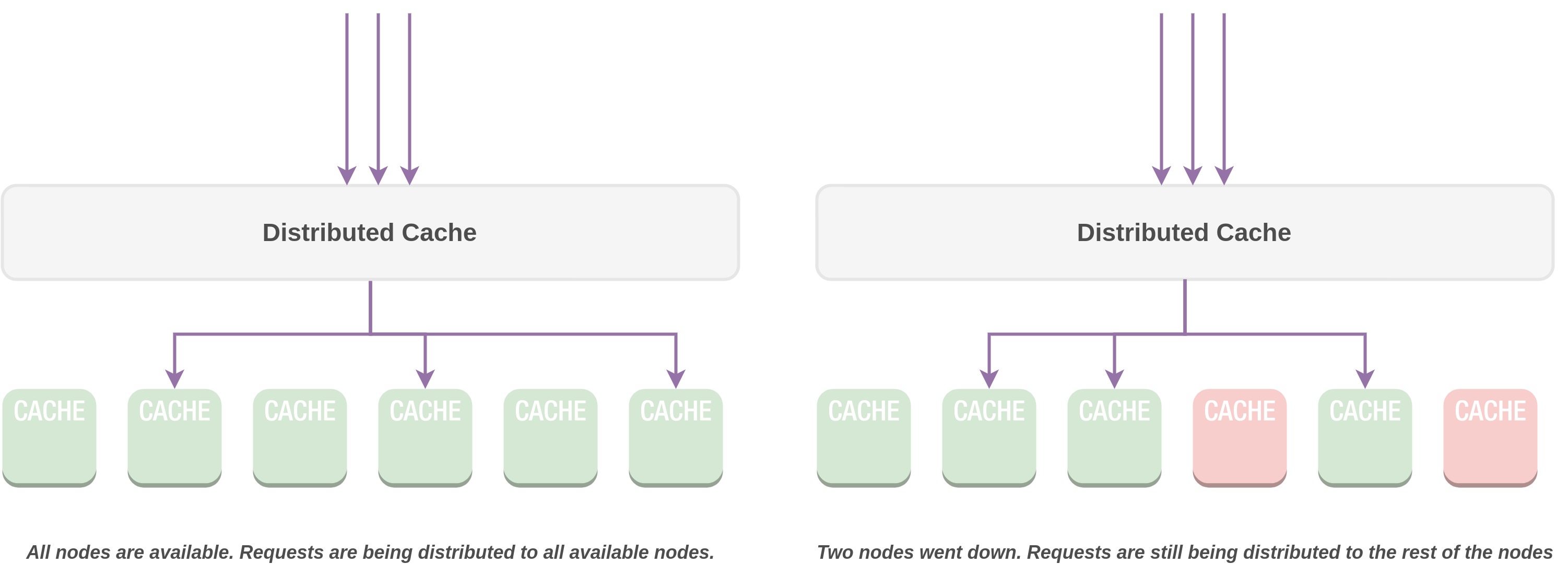
Use Cases
Optimizing Database Performance with Caching
Efficient database management involves the strategic use of caching techniques. By integrating a cache layer in front of a database, essential data can be stored in-memory, effectively minimizing both latency and the overall load on the database. This proactive caching approach significantly mitigates the likelihood of encountering a database bottleneck, ensuring smooth and responsive system performance.
Achieving Application Statelessness through User Session Storage
To maintain a seamless user experience even in the face of instance failures, a stateless approach is adopted by storing user sessions in the cache. By doing so, the risk of losing user states due to instance outages is mitigated. In the event that an instance becomes unavailable, a new instance is promptly initiated. This fresh instance retrieves the user's session data from the cache, seamlessly resuming the session's progression without causing any noticeable disruption to the user.
Facilitating Inter-Module Communication and Shared Storage
In-memory distributed caching plays a pivotal role in enabling seamless message communication among diverse microservices operating collaboratively. By storing shared data frequently accessed by these services, the cache effectively establishes a fundamental communication infrastructure for the microservices ecosystem. Moreover, this distributed caching paradigm extends its utility beyond communication, serving as a robust NoSQL key-value primary application datastore in specific scenarios, thereby showcasing its versatile role in bolstering efficient microservices architecture.
Real-Time Data Stream Processing and Analytics
Unlike conventional methods that involve storing data before conducting analytics (batch processing), utilizing a distributed cache allows us to seamlessly process and analyze data in real-time. This real-time data processing proves invaluable across various scenarios like detecting anomalies, monitoring fraud, retrieving real time statistics in a multiplayer online game, offering instant recommendations, and swiftly handling payment transactions, among others.
Caching Strategies
Cache Aside
When data is required, the application's initial search occurs within the cache. If the data is located in the cache, it's promptly delivered to the requester. Alternatively, if the data isn't found in the cache, it's fetched from the database, stored within the cache for future use, and then provided to the requester.
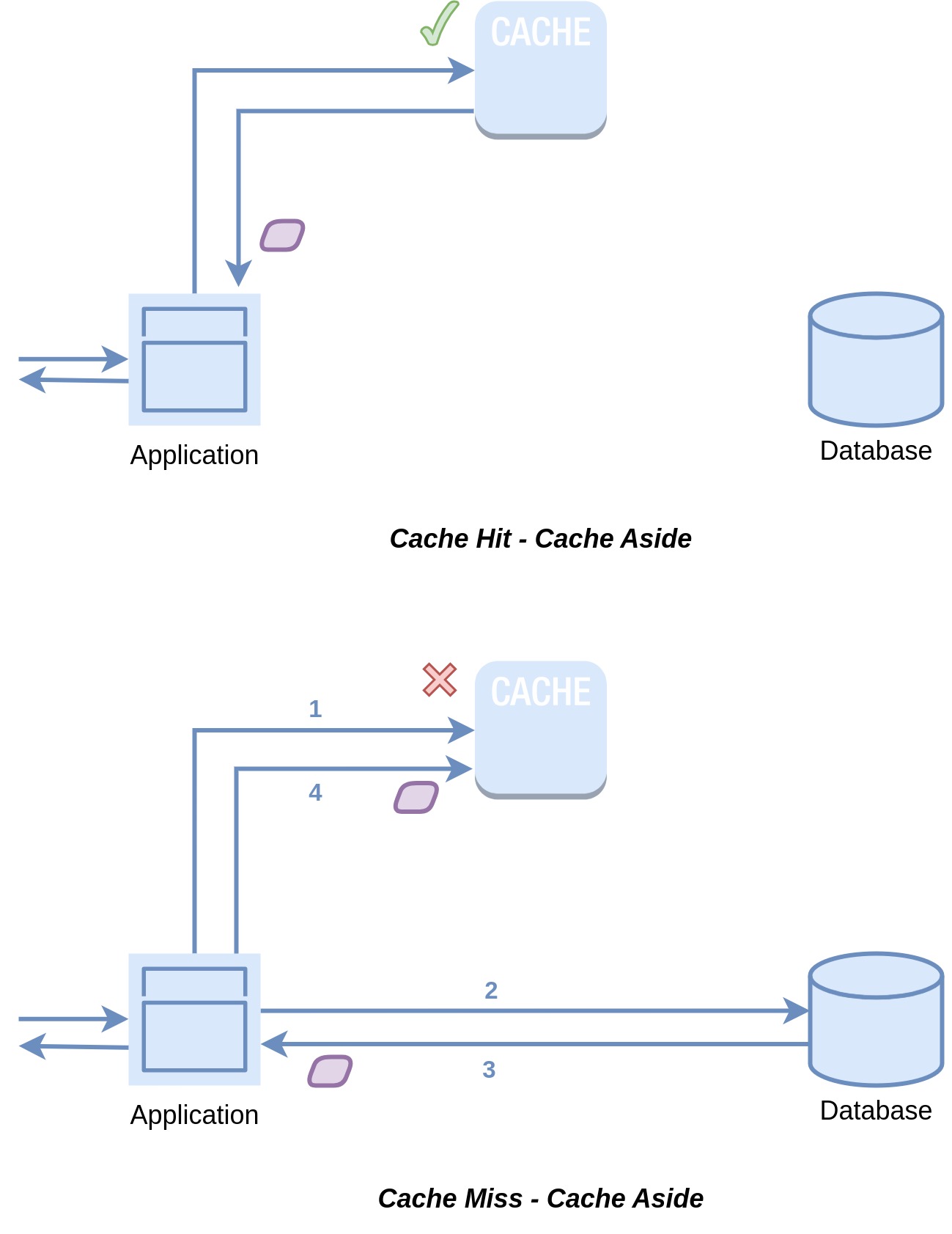
The Cache Aside approach is a general purpose approach that excels in read-heavy use cases. Widely adopted tools like Memcached and Redis are usually used to implement this. It is resilient to cache failures because when the cache is unavailable, the application loads data directly from the database although its performance could suffer under heavy loads. In this approach the data model in the cache doesn't need to match the data model of the database which could be very useful in different scenarios. On the flip side, Cache Aside is commonly employed with the write-around strategy, which can lead to inconsistencies between the cache and the database. To address this, a Time-to-Live (TTL) mechanism is often used to make sure stale data does not live forever in the cache. To ensure greater consistency for specific use cases, it's essential to adopt a more robust cache invalidation strategy, which we'll delve into shortly.
Read Through
In a read-through cache, when you look for data that isn't in the cache, the cache itself will automatically fetch the data from the main storage and save it before giving it to you. On the other hand, with cache-aside, you have to fetch data from the database yourself and then store it in the cache. In read-through, the caching process is usually managed by a library or cache provider, which handles the logic of getting data from the database and placing it in the cache.
Read-through caching works really well when you're frequently asking for the same data and you do a lot of reading. But there's one thing to watch out for: the first time you ask for some data, it might not be in the cache yet, which could slow things down a bit as it's fetched. One way to tackle this is by pre-loading the cache manually, a bit like warming it up. However, just like cache-aside, there's also a chance that the data in the cache might not match what's in the database.
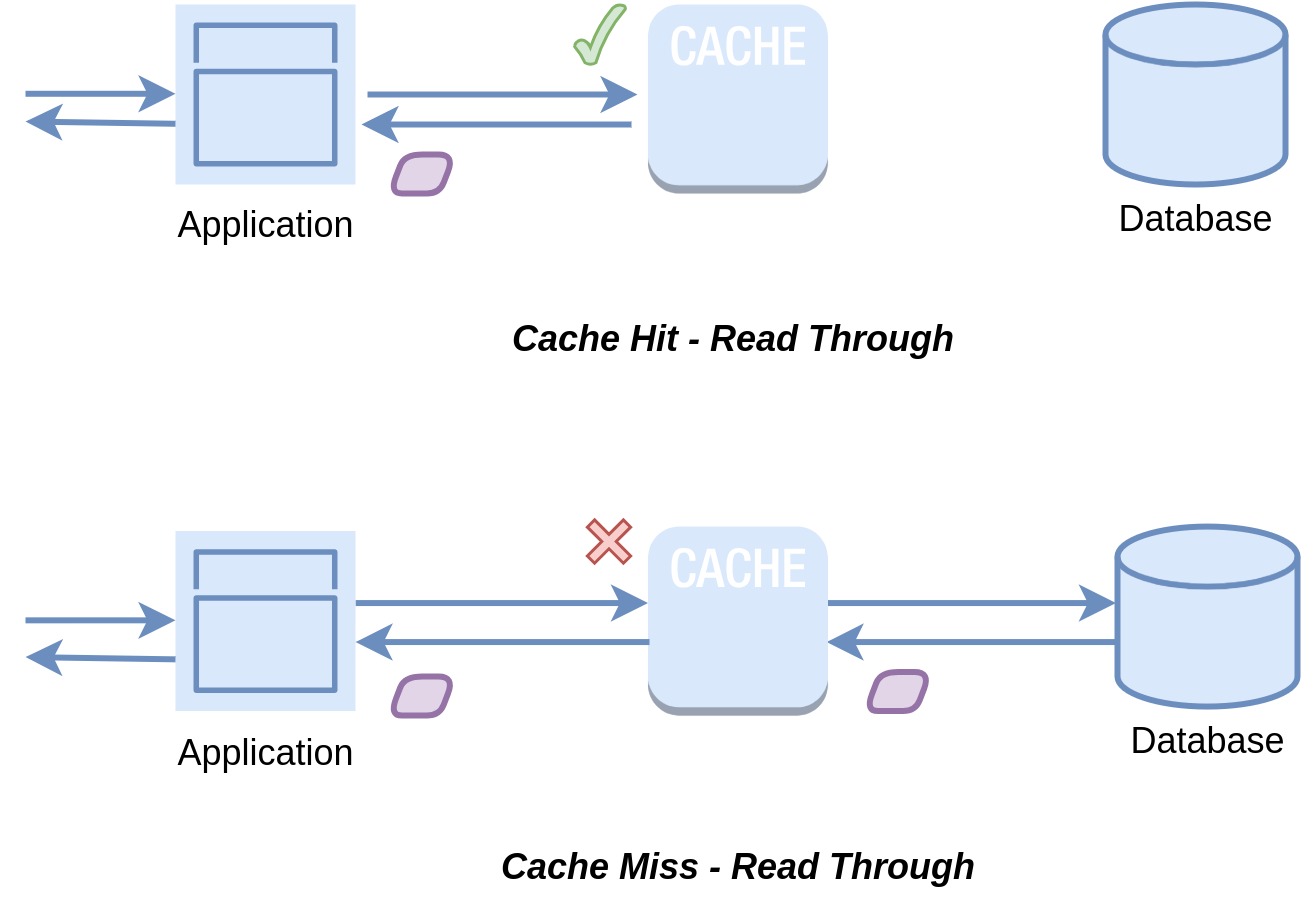
While read-through and cache-aside share similarities, they have distinct features to consider:
| Cache Aside | Read Through |
|---|---|
| Application to retrieve data from the database and places it in the cache | Library or cache provider is responsible for reading from the original database |
| Data model in the cache can be different | Data model in the cache has to be similar to the database |
Read-through caching shines when dealing with read-intensive tasks, particularly for frequently requested data like news stories. However, it's worth noting that the first data request typically triggers a cache miss, adding a slight delay due to data loading. To address this, we can "warm" the cache manually through queries. Just as in cache-aside, inconsistencies between cache and database are possible, with solutions often involving the write strategy.
Write Around
In this strategy, data is not immediately stored in the cache upon write operations. Instead, it bypasses the cache and is directly written to the main storage without writing anything in the cache. Upon subsequent read requests to the cache, the cache or the application, depending on which read strategy is used, will load the data from the database and fill the cache with the data.

Write-Around Cache works well when paired with read-through and is especially useful when you're dealing with scenarios where recently written data is not read immediately. Since the cache doesn't store recently written data, so if you're trying to read data you just wrote, you might not find it in the cache, resulting in a cache miss. This strategy works well for scenarios like logging systems, where new data is constantly generated but isn't immediately accessed. Similarly, in applications that involve periodic updates or data accumulation, such as financial transactions or sensor data recordings, Write-Around Cache can be a good choice. Additionally, when dealing with data that might be needed in the future but isn't frequently read in the present, such as historical records or backups, Write-Around Cache offers an efficient way to manage resources. By reserving cache space for the most frequently accessed data, Write-Around Cache ensures optimal performance, making it a favorable approach for these kinds of use cases.
Write Through
In the write strategy, data is initially written to the cache before being stored on the database. The cache is seamlessly integrated into the database pipeline, ensuring that all write operations flow through the cache before reaching the main database. This process guarantees that the cache remains synchronized with the primary database, maintaining a high level of data consistency.
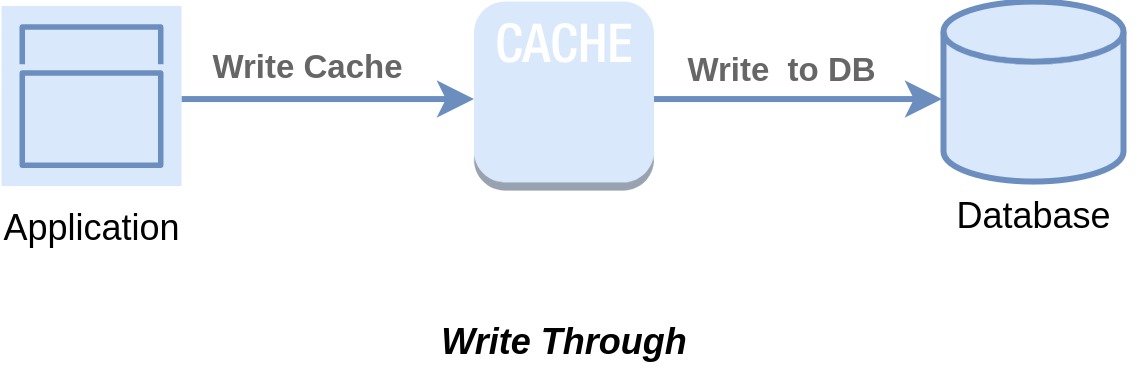
The data flow works as follows:
- The application directly writes the data to the cache.
- The cache subsequently synchronizes the data with the main database. Upon completion of the write process, both the cache and the database hold identical values, thus ensuring persistent consistency within the cache.
Write-through caches might seem to slow things down due to an extra step: data first goes to the cache and then to the main database, involving two write actions. However, when combined with read-through caches, we get the benefits of both approaches. Plus, this combination ensures data consistency, which means we don't need to worry about cache invalidation, as long as all database writes go through the cache.
A great example of this read-through / write-through cache concept is DynamoDB Accelerator (DAX) from AWS. It works between your application and DynamoDB, enabling reads and writes. If you're thinking about using DAX, just make sure you're familiar with its data consistency model and how it interacts with DynamoDB to get the full picture.
Write-Back or Write-Behind
Write-Back, also known as Write-Behind, is a strategy that solves one of the problems with Write-Through that is overhead of the double write operation. This approach is very similar to Write-Through but one big difference is that in this approach the application continuously writes to the cache without waiting for the data to be written in the database. Rather the data is queued to be stored on the database asynchronously. In Write-Through strategy, the data updates are synchronously applied to the main database, whereas in Write-Back, these updates occur asynchronously. This means that, for applications, Write-Back provides faster writes, as only the cache needs updating before responding.
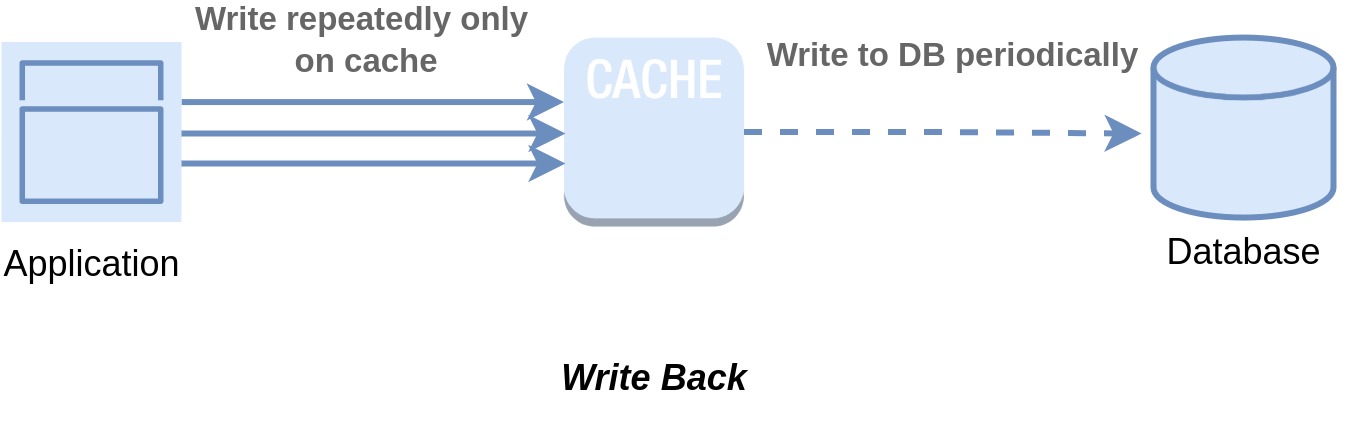
As we've seen, a Write-Through system can face performance slowdowns due to simultaneous write operations. Imagine if updates could be stored and gathered in the cache, and then applied collectively to the database in a batch at a specific time. This approach would unquestionably lighten the load on the database. Write-Back uses this idea to take the strain off the database when the write operations are happening very frequently. By adopting this idea, this strategy lessens the burden on the database significantly, especially when write operations occur frequently in the system.
There are a couple of ways in which the cache can apply the updates on the database. It can wait for a predefined amount of time before applying all updates in batch or it can wait for a predefined number of updates to accumulate before applying all the updates to the database in batch.
Write-Back Cache is a great strategy for scenarios with substantial write activity. This method bolsters write performance by asynchronously batching writes to the database, keeping the database from being overwhelmed with constant write requests. When coupled with read-through cache, frequently updated and accessed data remains readily available in the cache. This approach also offers a level of resilience against database downtime. By utilizing batching, it minimizes write requests to the database, which can lead to reduced costs, especially in cases where charges are based on request volume, such as DynamoDB. However, it's important to note that cache failure might lead to potential data loss, making careful consideration essential in its implementation. Example use cases for this strategy is online gaming, IoT data handling.
Refresh Ahead
When data is cached, it stays there only for a certain period. Once the data expires, the cache removes it automatically. This can cause a "cache miss," slowing things down because the data then needs to be fetched from the main database, which takes longer. Now, think about something like a popular news article. If many people try to read it simultaneously, they'll all face cache miss and end up fetching the data from the database, causing a slowdown known as the "thundering herd” problem.
Refresh-ahead comes to the rescue by taking a proactive approach. It fetches the data before it expires, like getting ready for the crowd before they all arrive. This ensures that frequently accessed data, or "hot data," stays in the cache, preventing cache misses and keeping performance in tip-top shape.
There are a few ways refresh ahead can be implemented. The first way is to run a background job that will refresh the cache with hot data at regular intervals.
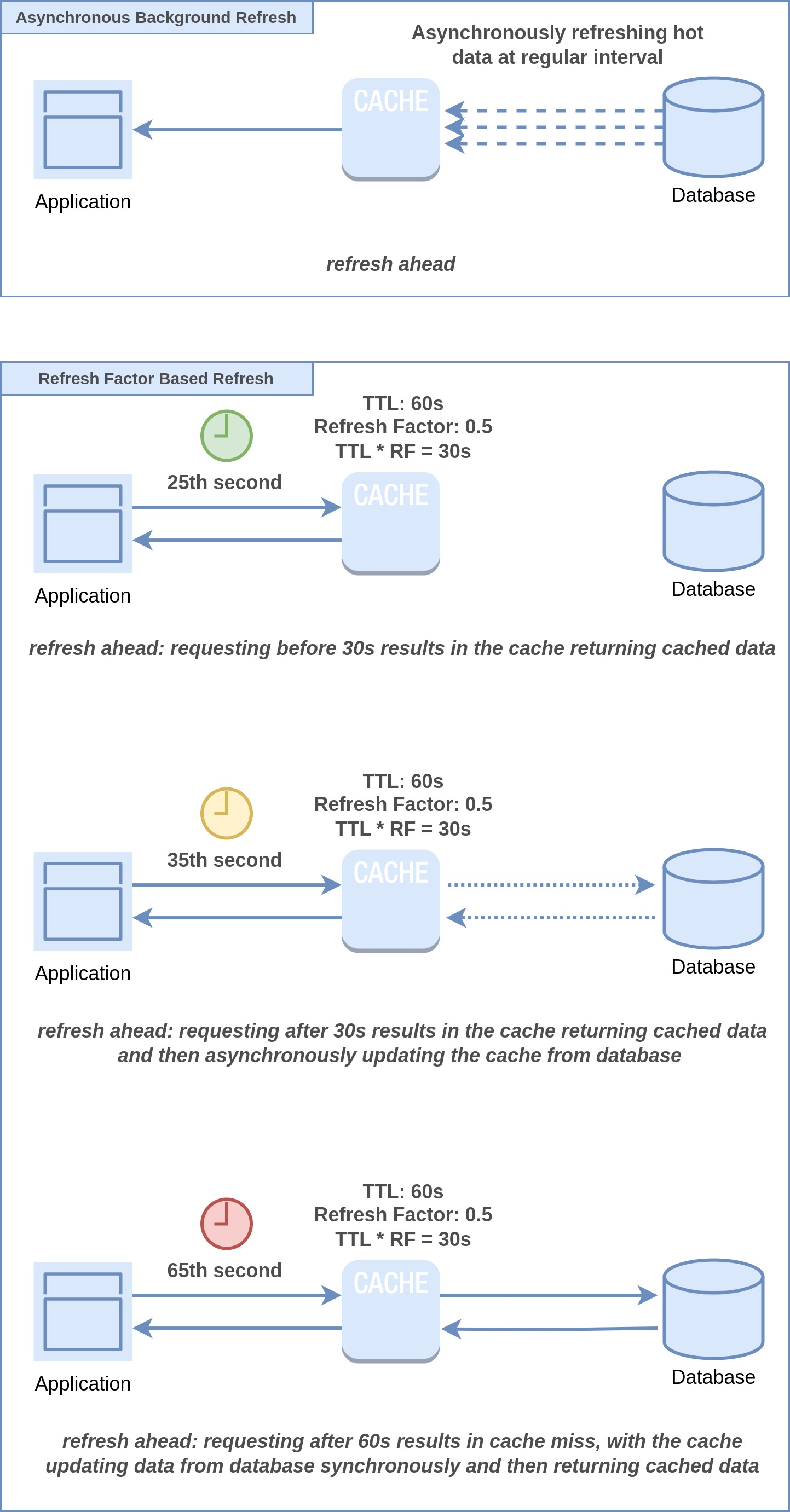
Another approach involves using a "refresh factor" to decide when the cache should ask for an update. By multiplying this factor with the time-to-live (TTL), we get a value that acts as a threshold. If the application asks for an item in the cache at a time that exceeds this threshold, they get it instantly, but the cache also starts asynchronously updating the data from the database in the background. This way, the cache can be up-to-date even before the expected expiration time. When the update is done, the item's expiration time is reset.
The refresh-ahead cache strategy offers several advantages to enhance data retrieval efficiency. It guarantees that frequently accessed data remains up-to-date before reaching expiration, mitigating the risk of working with outdated information. By proactively refreshing data just ahead of its expiration, this approach minimizes read latency, as cache misses are improbable due to timely refreshes. Moreover, it effectively resolves the "thundering herd" problem by preventing overwhelming load on the database from many users trying to access the same data simultaneously. This ensures a smoother user experience by evading cache misses for concurrently requested data, ultimately alleviating the potential strain on the database.
Implementing the refresh-ahead cache strategy comes with complexities that need careful handling. Additionally, this strategy might put strain on both the cache and the database when many cache keys require simultaneous updates.
Cache Invalidation
"There are only two hard things in Computer Science: cache invalidation and naming things."
- Phil Karlton
Cache invalidation plays a crucial role in maintaining the accuracy and reliability of cached data within various systems. As data undergoes changes in its original source, cached copies can quickly become outdated, potentially leading to inaccuracies in the information presented to users. Cache invalidation strategies address this challenge by efficiently updating or removing cached data to ensure it aligns with the latest updates in the source data. This process ensures that users interact with current and reliable data while benefiting from the performance enhancements offered by caching systems.
Inaccuracies in the cache can happen due to many reason. The most common being the underlying data being changed. The stale data stays in the cache until it expires. Some inconsistencies occur due to the inherent nature of distributed systems.
How Inconsistencies Form
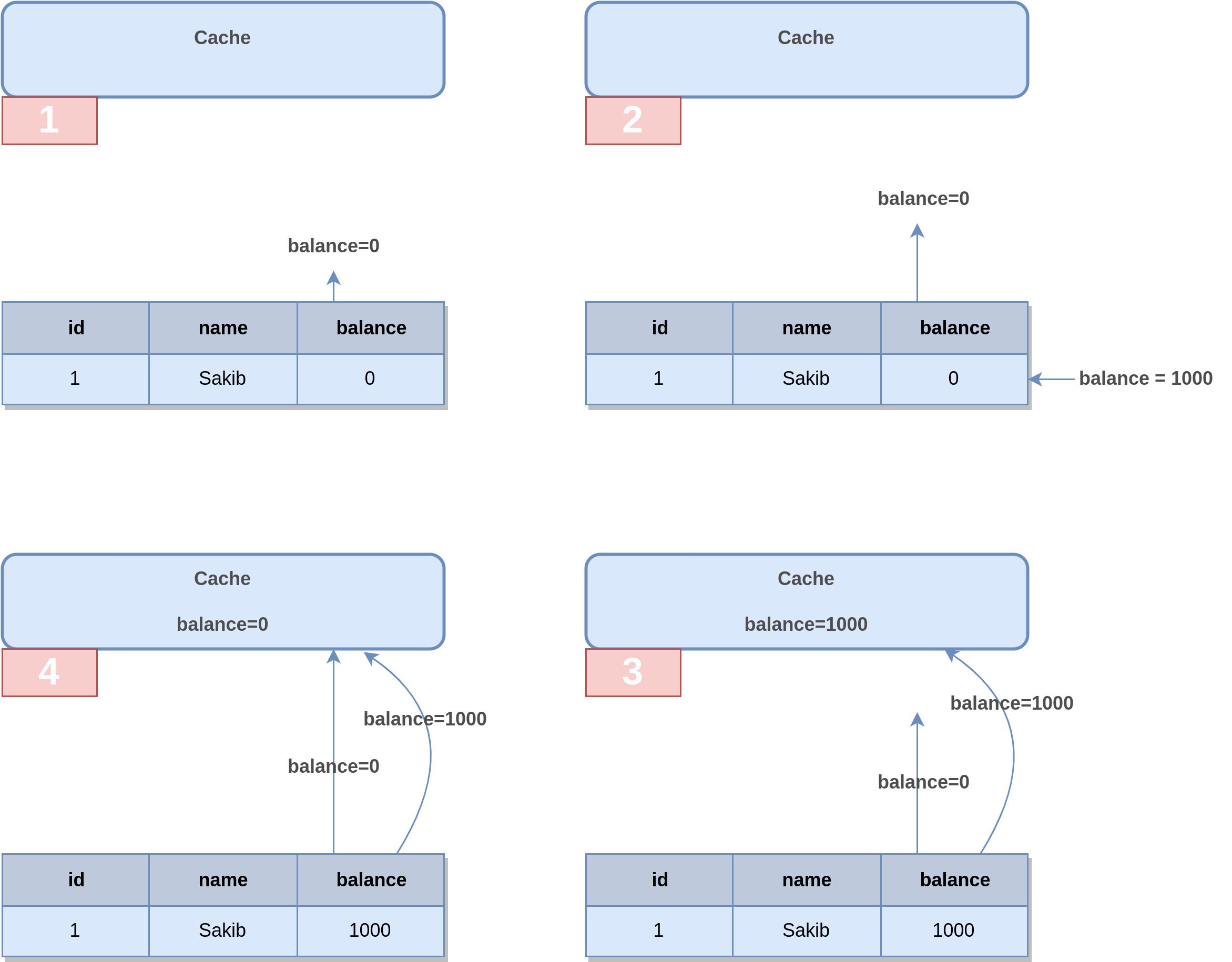
Imagine a scenario where a user requests to view their account balance, but the cache doesn't yet have that balance stored. As a result, the balance is fetched from the database to fulfill the user's request, subsequently stored in the cache for future reference. Concurrently, another user deposits $1000 into the user’s account, nearly coinciding with the initial read request.
As the response to the read request is en route, the database receives an update reflecting the new balance of $1000. Meanwhile, a cache invalidation event is triggered, signaling the cache to refresh its contents. The cache promptly updates the balance to $1000. However, the initial response, still in transit, eventually arrives. Unfortunately, due to timing, it carries the outdated balance of $0, overwriting the recent $1000 balance in the cache.
Versioning is a helpful technique to address such challenges. Each piece of data is assigned a version number. When data changes, the version number goes up. In the cache, an existing entry is replaced only if a newer version arrives. But, there's a catch. If an entry gets removed from the cache due to cache eviction, its version information is lost. Then, when a new version arrives, there isn't enough info to know if it's actually newer or not. This can cause confusion.
A cache entry can change in two ways: when it's added to the cache (cache fill) and when it's updated (cache invalidation). These two kinds of changes can happen at the same time, causing what we call race conditions. These conditions can lead to problems where things don't match up correctly. Plus, because a cache is a kind of temporary storage, sometimes we can lose important version details that help sort out conflicts. With all these things combined, cache invalidation becomes a complex topic in computer science, among other challenging factors.
Factors Contributing to the Challenging Nature of Cache Invalidation
Determining an optimal Time-to-Live (TTL) value is a delicate balancing act. Setting it too short results in frequent cache misses, disrupting the user experience, while setting it too long risks serving outdated data, creating inconsistencies and dissatisfied users. Consider a news portal with a cache system to manage user loads. Currently, the TTL for news articles is just 1 minute. However, this short interval presents a challenge: when a highly trending article's cache expires, a surge of simultaneous user requests causes cache misses, straining the database—a phenomenon known as the "thundering herd" problem. This issue recurs every minute. Alternatively, if the TTL is prolonged—say, 24 hours—any corrections made to an article won't reflect until the cache expires, exposing users to incorrect information and undermining the portal's credibility. Balancing these concerns is crucial for maintaining a seamless and reliable user experience.
Caches frequently store large datasets within a single cache entry. Consider an eCommerce application featuring an extensive product catalog cached for quick retrieval. Whenever a new product is added to the catalog, the application faces a dilemma: it can either clear the entire product catalog cache, despite most products remaining unchanged, or undertake the intricate and time-consuming process of updating the cache with the new product. Additionally, complications arise from the need to synchronize multiple cache locations affected by potential updates. For instance, modifying details of an existing product requires adjustments not only to the product catalog cache but also to the specific cache entry for that product's details. Essentially, any alteration of an entity in the source datastore must reverberate throughout all cache instances where the entity is referenced, yet determining which cache entries require invalidation due to changes in the source datastore presents a formidable challenge.
Ensuring cache consistency in distributed systems, which involve multiple interconnected servers or nodes, poses a significant challenge. In such setups, data is often replicated across various locations to enhance performance and availability. However, maintaining synchronization and coherence among these copies becomes complex due to factors like network latency, node failures, and concurrent updates.
Cache invalidation can be demanding for system performance, particularly when dealing with large caches. Incorrectly managed cache invalidation can lead to reduced system efficiency, counteracting the benefits of caching. Imagine you have a large cache storing frequently accessed data, and you frequently need to refresh the cache to keep the data current. If your cache invalidation approach triggers a massive update or removal of numerous cached entries simultaneously, it can consume significant time and resources, ultimately hampering overall performance.
Cache Invalidation Techniques
- Cache Expiration: This method involves setting a Time-to-live (TTL) value for each cache entry. Once this predefined period elapses, the cache entry automatically becomes invalid and is removed from the cache system. This is the most basic form of cache invalidation.
- Event-Driven Setup: Event-Driven Invalidation involves the initiation of cache invalidation actions based on particular events, such as updates in the database or alterations to external data sources. This form of cache invalidation is triggered by specific system events, ensuring that cached data remains accurate when tied to particular events or changes in state. The system works using a pub/sub model where the system subscribes to the events. Anything that changes the underlying data source must publish an event indicating the data source has changed. The system consumes these events and invalidate related cache entries from the cache.
- Polling: This approach involves cache nodes regularly checking the source data for any modifications and subsequently invalidating outdated data.
- Refresh-Ahead: Refresh-Ahead is a cache invalidation as it invalidates cache entries before they expire to keep the cache fresh.
- Write-through: Write through is also a cache invalidation strategy because all update operation first updates the cache and then the database is updated.
- Write-back: Write back is also a cache invalidation strategy because updates are flushed onto the cache constantly and then later at some point updates are stored into the database every once in a while (asynchronously).
- Versioning: Versioning can be considered when invalidating cache entries to maintain ordering and to resolve conflicts. Underlying data can maintain a version that changes as the data change. Cache should only be invalidated by a version that is higher than the version in the cache.
Cache Eviction Strategies
Cache eviction is the process of selecting which data to remove from the cache when the cache is full or needs to make room for new data. Cache eviction is usually done by using some algorithm or policy that determines the priority or the order of the data to be evicted. There are different types of cache eviction algorithms, such as least recently used (LRU), least frequently used (LFU), first in first out (FIFO), or random. A common best practice is to use cache eviction that maximizes the cache hit rate and the cache efficiency, such as using LRU, LFU, or a combination of these methods.
Cache operates within a limited memory space. As this space gets full, making room for new cache entries requires removing existing ones. Cache eviction manages this process by following specific rules. Various eviction policies, such as Least Recently Used (LRU), Least Frequently Used (LFU), First In First Out (FIFO) or random selection etc, guide which cache entries to remove. To optimize cache performance, it's advisable to adopt eviction methods that increase cache hits, like LRU, LFU, or a combination of these tactics.
- Least Recently Used (LRU): The eviction policy is based on tracking the timestamp of the most recent interaction with each cache entry. Whenever a new entry is added to the cache or an existing one is accessed through a cache call, its last used timestamp is updated to the current time for that entry. This means that the entry that has been accessed or added the longest time ago will have the oldest timestamp. When the cache reaches its limit and needs to evict an entry to make space for a new one, it selects the entry with the oldest last used timestamp, indicating that it has been the least recently used.
- Least Frequently Used (LFU): The Least Frequently Used (LFU) eviction policy operates by keeping track of how often each cache entry is accessed. Whenever an entry is retrieved, its hit count increases. When the cache is full and a new entry needs space, the LFU policy identifies the entry with the fewest hits, implying it's been accessed the least. This entry is then evicted, ensuring that the cache prioritizes retaining frequently accessed items and making room for new ones.
- First In First Out (FIFO): The First-In-First-Out (FIFO) eviction policy operates by removing cache entries in the same sequence they were added. When a new entry is added using a put call and the memory store is at its maximum capacity, the entry that was initially placed in the store—the "First-In"—is the one considered for eviction, following the principle of "First-Out." This algorithm is ideal when using an entry diminishes its future likelihood of use. A good example is an authentication cache, where older authentication data is less relevant, and newer entries are prioritized to accommodate changing user interactions.
- Last In First Out (LIFO): The Last In First Out (LIFO) eviction policy removes the most recently added data entries from the cache first. In this policy, the items that were added last are the ones that get evicted when the cache is full. It operates based on the principle of "last in, first out," similar to a stack of items where the last item placed on top is the first one to be removed. This policy doesn't consider how often an item has been accessed or its historical popularity; it simply prioritizes removing the most recently added items to make room for new entries.
- Most Recently Used (MRU): The Most Recently Used (MRU) eviction policy removes the most recently accessed items first, which makes it suitable for scenarios where older items are more likely to be used. This policy ensures that older content stays available while removing the most recently accessed items to make space for new content. It is useful in scenarios with sequential scan.
Cache Monitoring
Cache monitoring is essential in maintaining optimal performance and efficiency within a caching system. By systematically gathering and analyzing metrics and statistics related to cache, this practice helps in detecting and resolving cache-related issues. Using different tools and methods, such as logging, dashboards, alerts, and custom logic, cache monitoring offers a comprehensive view of key operational facts, such as cache size, cache hit rate, latency, throughput, errors, and evictions. Using this metrics and data about the behavior of the caching system, we can evaluate how effectively the system is running. If necessary, we can fine tune the configurations, make more adjustments like changing the cache eviction policy to make the system more consistent over time.
Distributed caching stands as a vital solution for optimizing system performance by reducing latency and enhancing scalability. Throughout this article, we explored various caching strategies and eviction policies that cater to diverse use cases. Additionally, we delved into the complexities that make effective caching a challenging endeavor. By understanding the intricacies of caching strategies, eviction policies, and the inherent challenges of distributed caching, informed decisions can be made regarding the adoption of distributed caching. If for a specific use case, the advantages outweigh the challenges, adopting distributed caching would undoubtedly lead to a much better user experience.
Explore More
Topics
Are you new? Start here
Microservice Architecture
Patterns & best practices to achieve scalability, flexibility, and resiliency.
Event Driven Architecture
Embrace Scalable, Responsive, and Resilient Systems through Event-Driven Paradigm.
System Design
Explore modern software solutions to scale to the horizon.