As we break down a monolithic application into smaller microservices, we encounter a challenge: keeping track of the increasing number of network locations for these microservices. Unlike before, where communication happened through in-process function calls, we now need to know the IP address, port, and protocol to communicate with another service. Microservices operate in a dynamic environment, making this issue more complex.
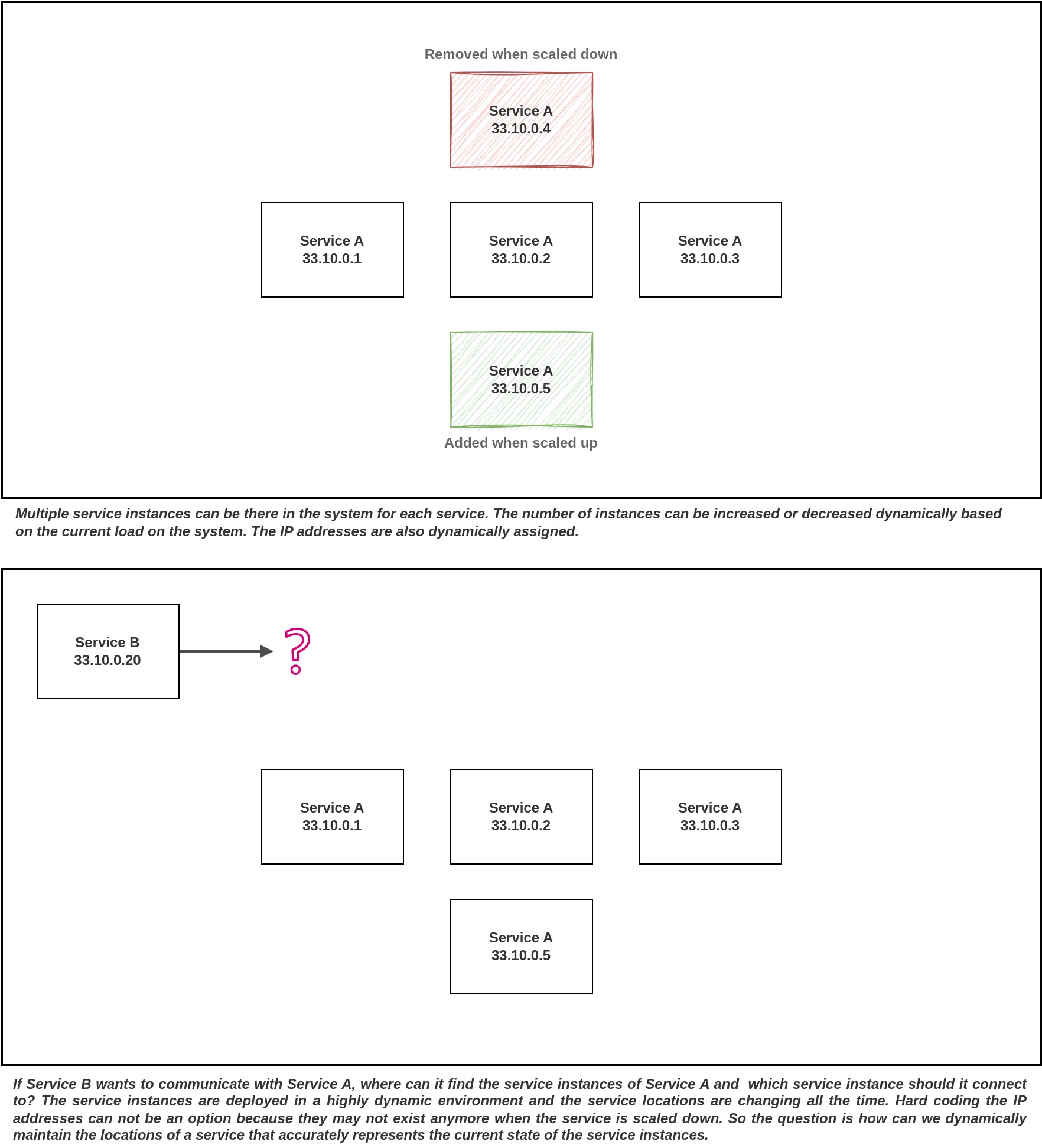
In cloud computing environments, a single service can have multiple instances running, and these instances are assigned network locations dynamically. IP addresses aren't fixed and can change due to auto-scaling, failures, or upgrades. Additionally, the number of services can fluctuate based on application load. Managing a comprehensive list of the network locations of all the active instances for each service becomes a cumbersome task.
To address this challenge, we need a solution where there is a centralized service or infrastructure component responsible for maintaining a list of active instances and their network locations for each service. Client services can then query this central source of truth to obtain a list of all active instance network locations for a specific service. Such a solution eliminates the need for discovery logic within the application code, reducing dependencies on specific network locations. It also allows for the seamless addition or removal of services without requiring modifications to other services.
Service Discovery Patterns
Client-Side Discovery
In this approach, it's the client service's responsibility to explicitly fetch the list of network locations for the currently active instances of a service provider and perform load balancing to select one service instance to send the request to. The client achieves this by querying a service registry to identify the available service instances.
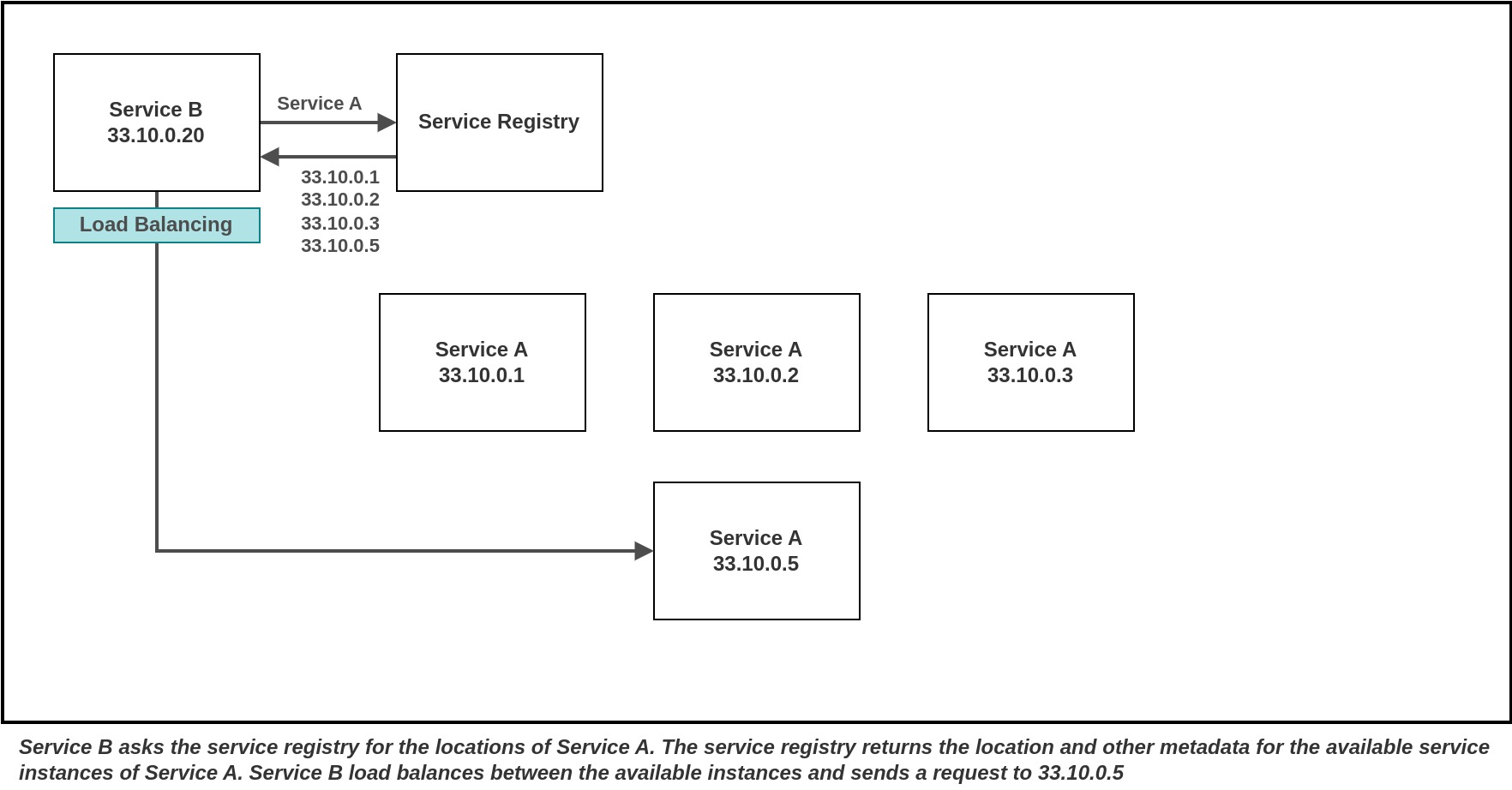
The service registry keep track of the active service instances for each services in the system. An example of a service registry is Netflix Eureka. Netflix Eureka is comprised of two main components: the Eureka server, which serves as the service registry, and the Eureka client. The Eureka client simplifies the interaction with the server by managing load balancing and providing failover support.
Advantages of this approach include:
- Simplicity: It's a straightforward method.
- No Need for Load Balancers or Routers: It eliminates the necessity for additional load balancing infrastructure.
- Avoids Intermediate Hops: It streamlines communication without adding extra intermediaries.
- Cross-Environment Compatibility: It effectively handles scenarios where service instances are distributed across various environments, such as on-premises and cloud.
On the flip side, there are some disadvantages:
- Implementation Overhead: The discovery logic must be implemented in every service. If different services are coded in different languages, this logic needs to be replicated in each of those languages.
- Dual Calls: It requires two separate calls—one for retrieving service locations and another for the actual service request.
- Self-Management: The service registry demands self-management.
- Tight Coupling: It results in a level of coupling between the client and the service registry.
Server-Side Discovery
In the Server-side discovery pattern, the client is decoupled from the service registry, resolving a significant issue seen in Client-side discovery. In this approach, dedicated load balancing logic is not required for the client as the load balancing does not take place in the client service. Instead, a load balancer acts as an intermediary responsible for interfacing with the service registry.
Here's how it functions: The client initiates a request for a microservice through the load balancer. Subsequently, the load balancer consults the service registry to determine the location of the specific microservice. Finally, the load balancer re-directs the request to the appropriate microservice.
AWS Elastic Load Balancer (ELB) is and example of the Server-side service discovery pattern. ELB adeptly handles tasks such as registering new instances and automatically removing instances that are shutting down. It maintains an up-to-date view of currently active service instances and comes with a DNS name that serves as the primary service address. In practice, all the instances of a particular service can be grouped behind a load balancer. When a request is sent to the load balancer, it takes care of directing the request to one of the active instances. Importantly, the client only needs to be aware of the DNS names associated with the load balancers for the services. These DNS names can be easily provided in the application via environment variables.
The problem with this method is that we end up having a separate load balancer for each service in the system, and each of these load balancers requires ongoing maintenance. Even though there are multiple instances of a service running behind each load balancer, the load balancer itself becomes a potential single point of failure in the system. This means that if a load balancer fails, it can disrupt the entire service, even though there are backup instances. Additionally, having multiple load balancers can introduce some delays in communication between services. This is because when one service needs to talk to another, it has to go through its respective load balancer first, which can add some extra time to the process.
AWS suggest another way to implement service discovery when using ECS. You can read more about the reference architecture here.
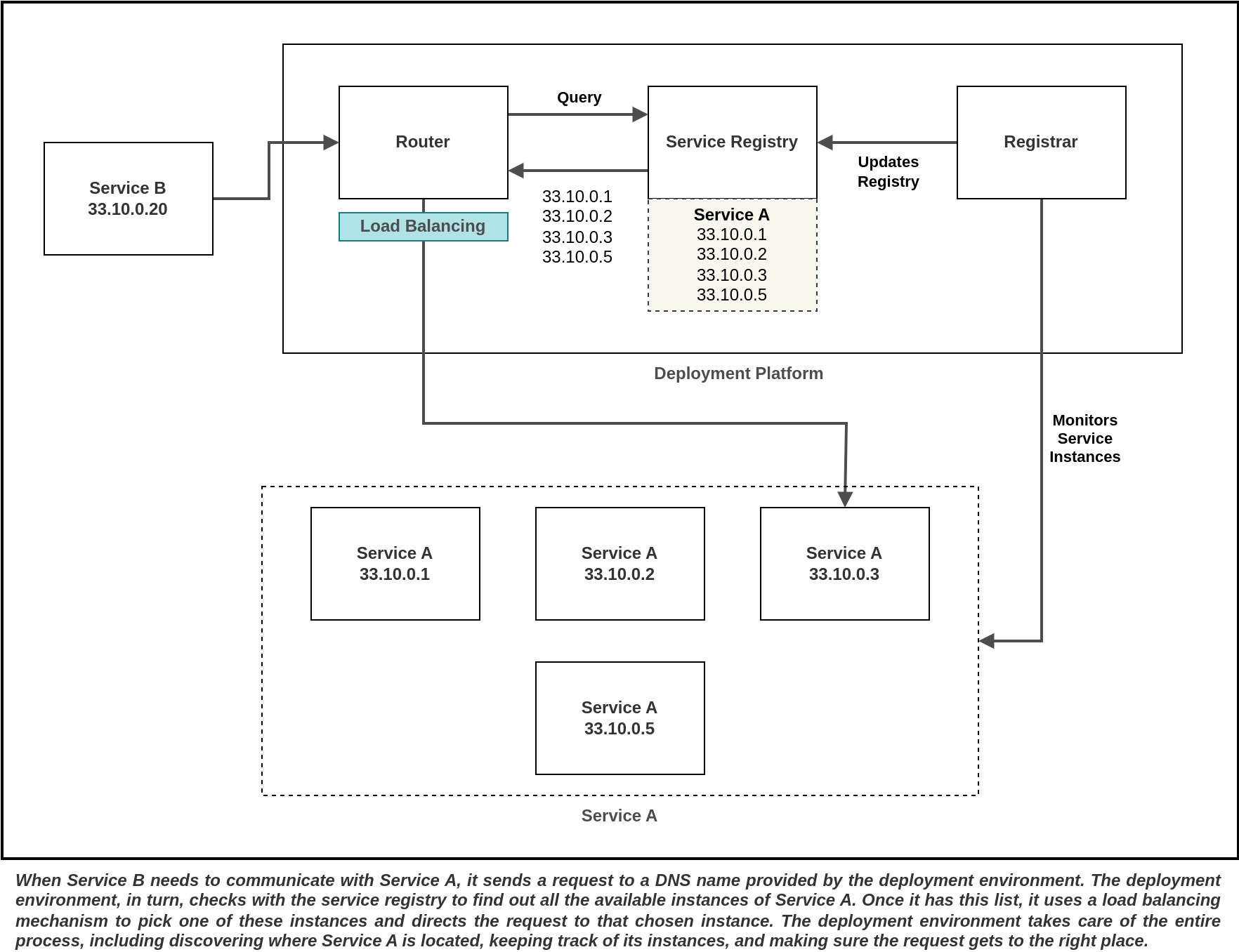
Modern deployment platforms often include a service registry and service discovery system as integral components. These platforms assign a DNS name and a virtual IP address to each service they host, with the DNS name resolving to the corresponding virtual IP address. When a service client needs to make a request, it directs that request to the DNS name. The deployment platform then takes care of automatically routing the request to one of the available instances of the service. Consequently, the deployment platform handles all aspects of service registration, service discovery, and request routing. The deployment platform maintains a record of the IP addresses associated with the deployed services. When a request is made to a specific service, such as the "order-service," the deployment platform automatically distributes the incoming requests among all the available instances of the "order-service" through load balancing. The deployment platform takes on the responsibility of handling the registration and de-registration of service instances with the service registry when service instances start up or shut down. This approach to service discovery offers significant advantages, as it entrusts the deployment platform with full control over all aspects of service discovery. None of the services within the system need to incorporate any service discovery code. This means that all services, regardless of the programming language or framework they are developed in, seamlessly gain access to service discovery capabilities. A limitation of relying on service discovery offered by the platform is that it can only locate services that are deployed using that specific platform. For instance, if we consider Kubernetes-based discovery, it will only function for services that are running within the Kubernetes environment.
DNS Based Service Discovery
DNS (Domain Name System) allows us to associate a name to the IP address of one or multiple machines. We can designate a specific name for a particular service and direct this name to a load balancer, which in turn distributes incoming requests to several active instances of that service. However, this approach requires us to regularly update the DNS records whenever we deploy new instances or scale the service to ensure accurate routing of traffic.
DNS's primary benefit lies in its extensive usage and high level of comprehension within the IT community. Furthermore, it is language-agnostic, ensuring compatibility with nearly every technology stack in existence. Updating DNS records can be a tricky task because they get cached in multiple places, and each entry has a "Time to Live" (TTL) setting, which determines how long the DNS information remains valid. Until the TTL expires, clients may hold onto outdated DNS entries. To overcome this challenge of stale entries, one effective approach is to link a load balancer to the DNS entry and have it manage the connections to the service instances. When a new instance is deployed, it gets registered with the load balancer, and if an instance is taken offline, the load balancer removes it from the pool of active instances. This way, the load balancer helps ensure that traffic is directed to the right service instances, even as the system evolves.
Service Registry
A service registry plays a crucial role as a centralized database containing all the services available in the system and their metadata. Its main purpose is to assist service consumers in finding and identifying the active instances of the services they want to interact with. Essentially, it acts as a sort of "phone book" for services, making it easier for different parts of a microservices system to find and connect to one another.
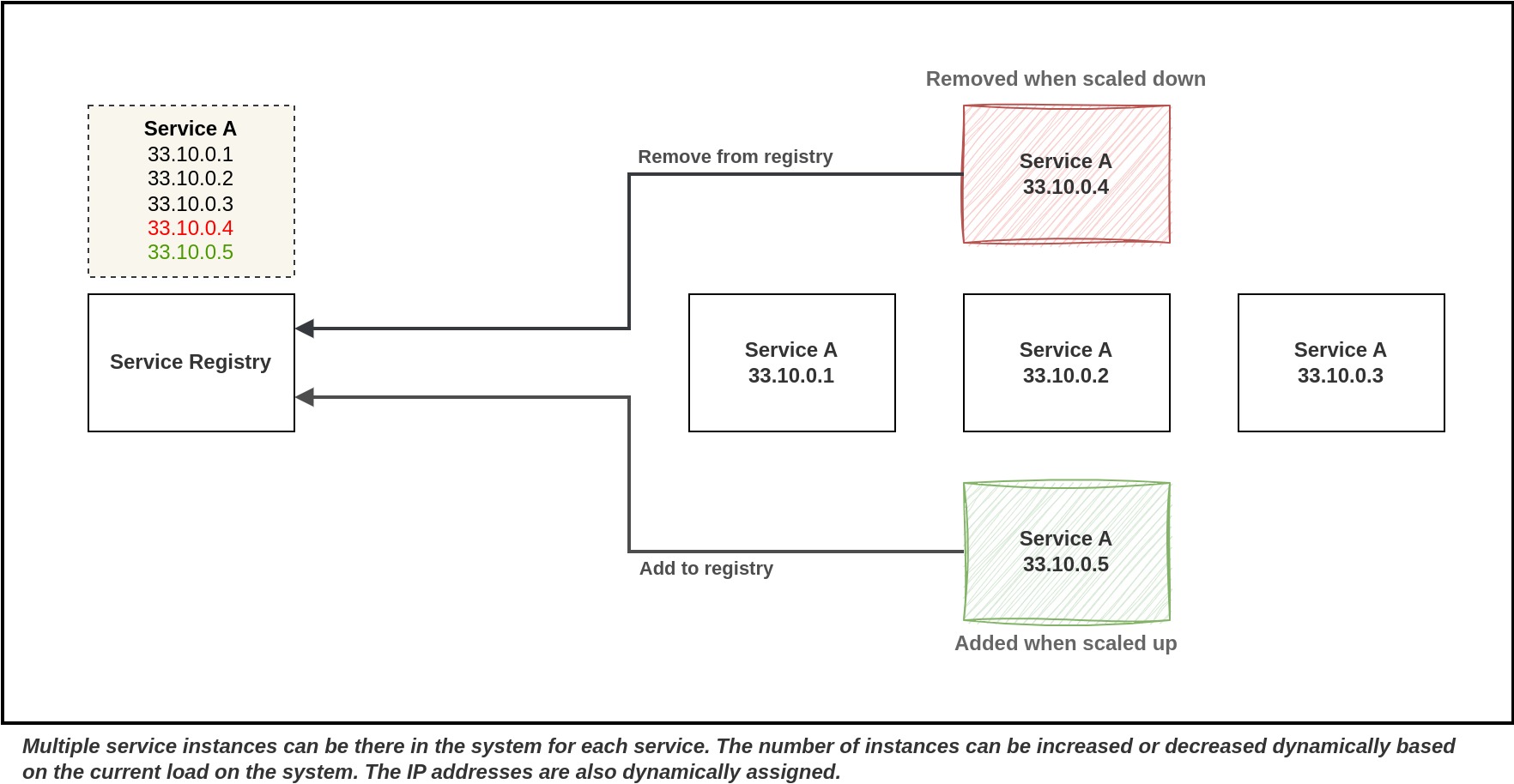
There are several key functions of a service registry:
Service Registration
When a new service instance is added to the system, it needs to be recorded in the service registry. This registration process involves providing details about the service instance, including where it's located, its availability status, and metadata such as version numbers, dependencies, and other pertinent information. Service registration typically follows one of two following patterns.
Self-Registration
In this particular approach, services take on the responsibility of registering themselves with the service registry and providing regular updates to indicate that they are still operational. When a service instance is shutting down intentionally, it should first remove its registration from the service registry. However, if a service server suddenly crashes or becomes unresponsive without the chance to deregister itself, several problems can arise. One of these issues is that the service registry might still list the service as available, even though it cannot respond to requests. This can lead to errors or delays for service consumers trying to connect to an inactive service.
To address these issues, it's crucial to establish a system for detecting and handling unexpected service failures. One way to do this is by implementing "health checks" that periodically inspect the status of registered services. If a service is unresponsive or unavailable, it can be removed from the list of available services. Alternatively, service instances can periodically send "heartbeats" to signal that they are still functioning and update the timestamp indicating when the last heartbeat was sent. The service registry can then use a "timeout mechanism" that automatically eliminates services from its list if they haven't provided a heartbeat within a specific timeframe. These strategies work together to ensure that the service registry always maintains an accurate record of service availability, even when unexpected failures occur.
The self-registration pattern comes with both advantages and disadvantages. On the positive side, it's straightforward and doesn't require additional system components. However, a significant drawback is that it creates a tight coupling between service instances and the service registry. This means you must implement registration code for each programming language and framework utilized by your services, potentially adding complexity and maintenance overhead to your system.
Third Party Registration
In this scenario, a third-party registrar takes on the role of handling the registration and deregistration of a service instance in the service registry. When a service instance is initiated, the registrar registers it with the service registry. Conversely, when the service instance is brought down or shut off, the registrar takes care of removing it from the service registry. An example within AWS is the behavior of Autoscaling Groups, which automatically manage the registration and deregistration of EC2 instances with the Elastic Load Balancer. In Kubernetes, services are automatically registered and made available for discovery.
The third-party registration pattern offers several advantages and drawbacks. One significant benefit is the decoupling of services from the service registry. This means you can avoid the need to implement service registration logic for every programming language and framework employed by your development team. Instead, service instance registration is centralized and managed within a dedicated service. However, a drawback to this approach is that unless it's a part of the deployment environment, it introduces another critical system component that requires setup and ongoing management to ensure high availability.
Service Removal
When service instances shut down gracefully, they typically deregister themselves from the registry. However, in cases of unexpected failures where a service instance cannot perform this action, the service registry steps in. It employs monitoring mechanisms like health checks or timeouts triggered by missing heartbeat signals to detect unresponsive or inactive service instances. Once identified, the service registry removes these unavailable instances from its list of available services. This ensures that the registry continually reflects the real-time availability of services, safeguarding the overall stability and functionality of the system.
Service Discovery
Service consumers rely on the service registry to find the instances of the services they want to interact with. When a service consumer query the service registry for a service provider, the service registry provides a list of available instances for that service provider. The list of available services can be affected by various factors like load balancing or proximity to optimize the selection of the right service instance.
Service Health Monitoring
Service health monitoring in a service registry involves one of the following two mechanisms: health checks and heartbeats. Health checks are like periodic checks where the registry assesses the status of registered services. If a service fails these checks, it's flagged as unhealthy and removed from the registry. On the other hand, heartbeats are signals sent by service instances at regular intervals to indicate that they're still alive and well. If a service misses a few heartbeats and a the certain amount of time passes after the last heartbeat received, the registry considers it inactive and takes action accordingly. These combined methods help the service registry keep a close watch on service instances, ensuring that it always knows which services are operational and can respond to requests, even if there are unexpected failures in the system.
Service Management
Service registry is a centralized database containing information about the available instances of all services. It simplifies the process for a service instance to register itself and find other services it needs to communicate with. However, there are instances when we also require access to this information related to all services and their available instances in the system. To make this data accessible and consumable for us, one approach is to provide APIs that allow us to retrieve this information and integrate it into user-friendly interfaces. This way, we can easily access and use the service-related details we need.
Implementations
Netflix Eureka
Netflix Eureka is a powerful tool for implementing client-side service discovery and load balancing. It's comprised of two main components: the Eureka Server and the Eureka Client. The Eureka Server provides a set of REST APIs that allow services to register, deregister, send heartbeats, and inquire about other services. On the other hand, the Eureka Client simplifies the process for both service consumers and providers to interact with the Eureka Server, making it easier to find and use the services they need.
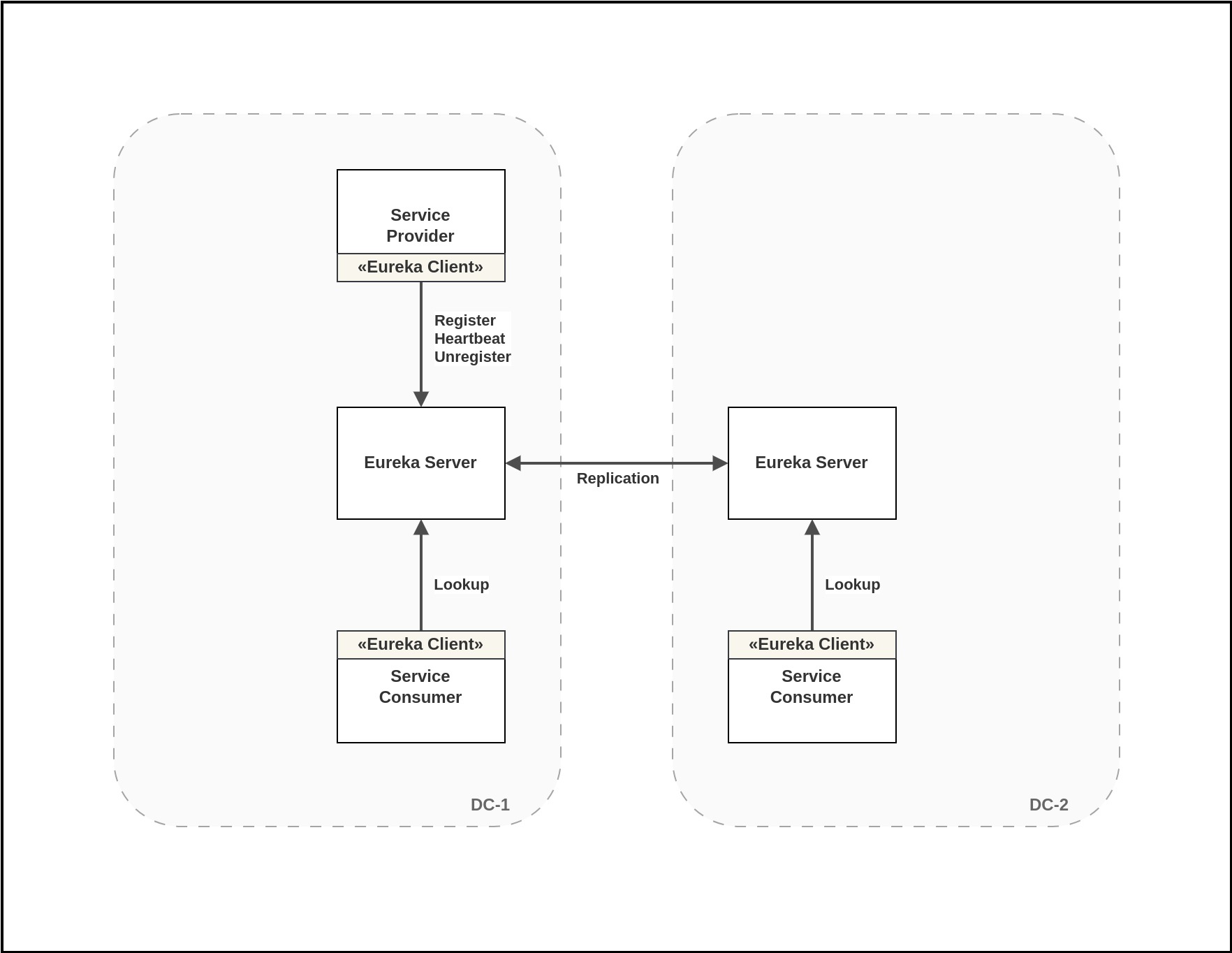
When service instances are deployed, they need to use the Eureka Client to register themselves with the Eureka Server. These instances also regularly send heartbeats to the server to maintain their registration. If an instance fails to send heartbeats for a certain period, the Eureka Server will automatically remove it from the list of registered services. When an instance is intentionally shut down in a controlled manner, it should first deregister itself from Eureka before shutting down completely. For services that need to find and communicate with other services, they can use the Eureka Client to query the Eureka Server for the available instances of a specific service. Once they have this information, they can directly connect and interact with the desired service instances.
Eureka's architecture prioritizes high availability over strict consistency. In this setup, a system can have multiple Eureka Servers that replicate data among themselves. This redundancy improves system availability and minimizes latency. Eureka Servers are designed to handle situations where some of their peers may become unavailable. Even in scenarios where there's a network partition that separates clients from the servers, the servers are built to withstand such challenges and prevent widespread outages. Eureka Clients, on the other hand, can store registry information locally in their cache. This means they can continue functioning even if all of the Eureka Servers become temporarily unreachable. This resilience in the architecture ensures that service discovery remains robust and dependable in the face of various challenges.
Consul
In a consul cluster, we have consul agents running either in client or server mode. Consul client agents are typically placed right alongside your service instances. These clients are the ones that communicate with the consul server agents on behalf of the service. Think of the consul client agent as the entry point for the consul server agents. The important service data, however, is only stored on the consul server agents.
The service consumer can query the consul client agent over HTTP and the client agent in turn can query the consul servers to get the result. The client conducts periodic health checks on the service provider to check if it is still healthy. In a Consul cluster, there can be multiple consul server agents. Only one server agent among the consul servers can be a leader. A leader server is elected using a consensus process, ensuring orderly handling of queries and transactions to prevent conflicts in multi-server setups. Servers not acting as leaders are called followers, forwarding requests to the leader, which replicates them to all servers for data redundancy. Consul servers use the Raft algorithm on a specific port to achieve consensus.
Service discovery is the backbone of microservice communication, ensuring reliable discovery of service instances and smooth communication between services in a highly dynamic deployment environment. As we've explored, service discovery techniques and strategies are essential for simplifying complex communication patterns and ensuring the scalability of microservices. By employing an appropriate service discovery technique, we can effortlessly and reliably establish communication between microservices, regardless of how dynamic the deployment environment may be. Some service discovery techniques even enable communication between service instances deployed in entirely different deployment environments. Choosing the most suitable service discovery approach for our specific use cases is crucial for ensuring the continued maintainability and reliability of inter-service communication.
Explore More
Topics
Are you new? Start here
Microservice Architecture
Patterns & best practices to achieve scalability, flexibility, and resiliency.
Event Driven Architecture
Embrace Scalable, Responsive, and Resilient Systems through Event-Driven Paradigm.
System Design
Explore modern software solutions to scale to the horizon.